External Search Providers
In CluedIn, an External Search Provider allows you to take input from data flowing through the processing pipeline and then lookup services (typically external API’s) as to enrich just a single particular entity.
Imagine you have an API that allows you to lookup a company by an Identifier, Name or Website and it would bring back more, enriched data so that you could extend what data you had internally on that entity. A good example would be Crunchbase, Duns and Bradstreet or Open Corporates. One can register for these API’s and lookup individual records via certain values and it may return zero or many results.
For example, imagine the company Oracle. Here is an example of a “before” enrichment.
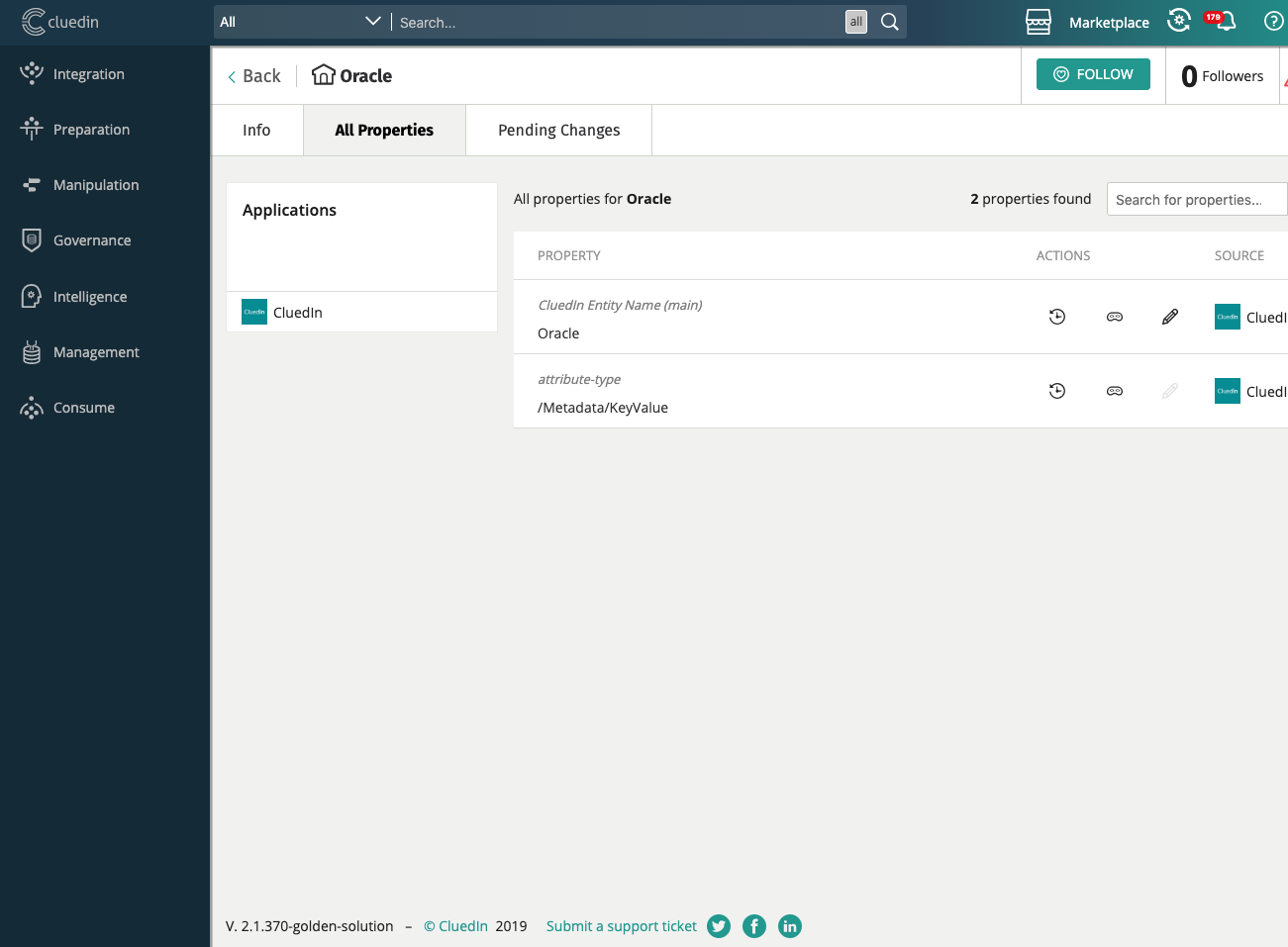
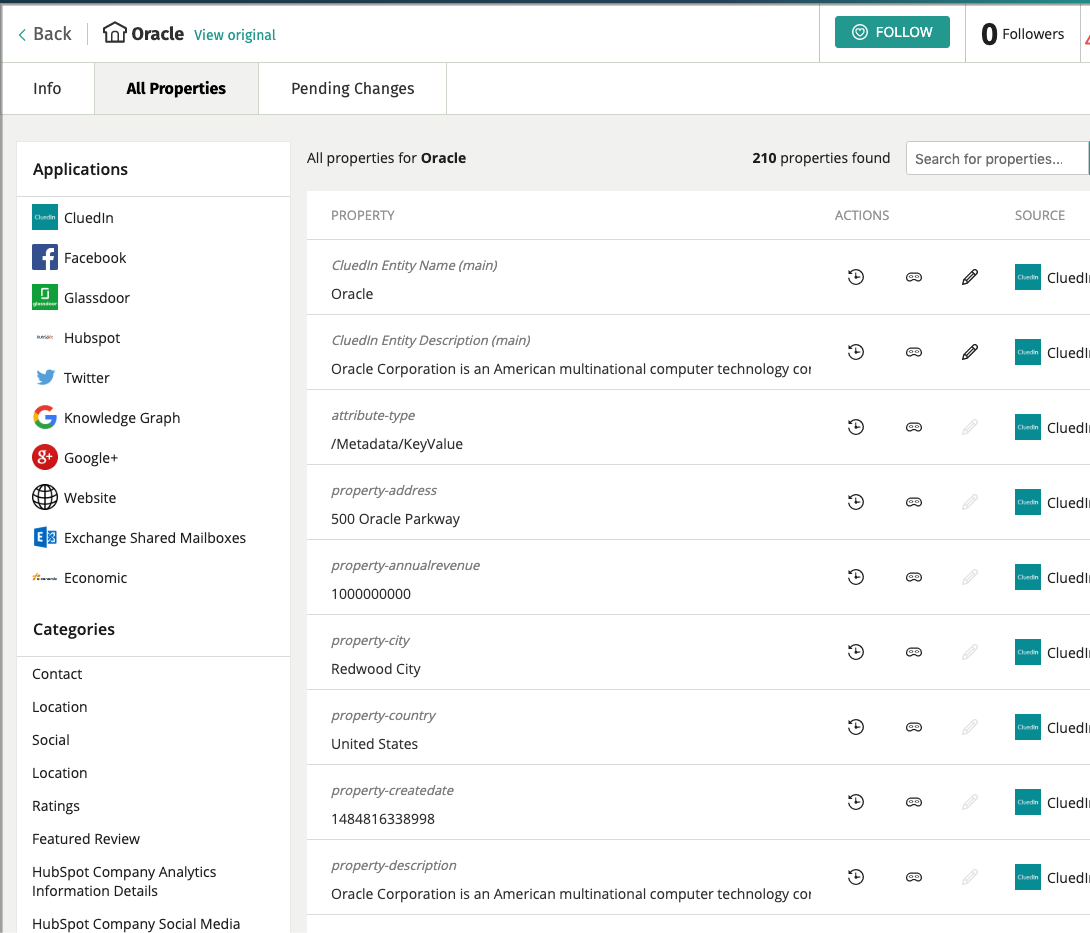
Here is the same record after 5 of the 35 prebuilt enrichers has been enabled.
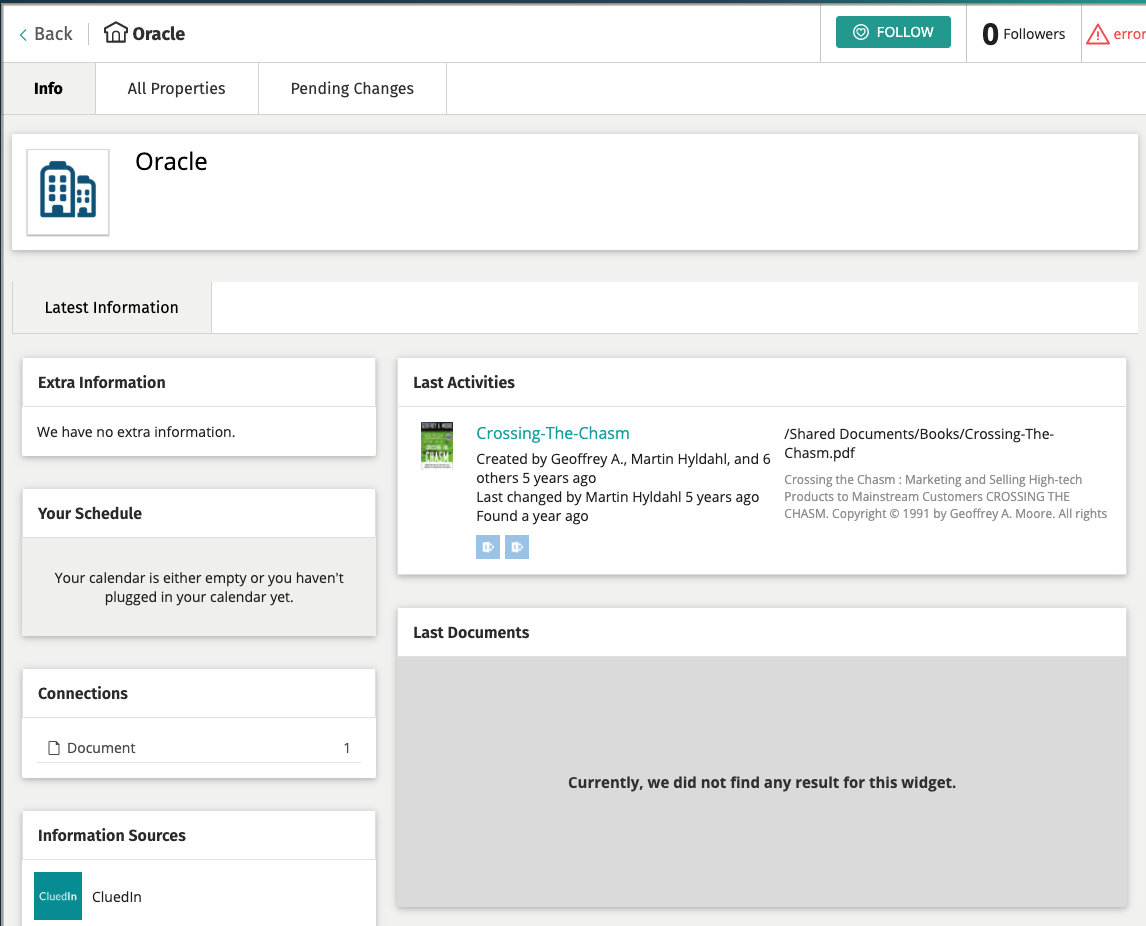
This is the un-enriched record from another view.
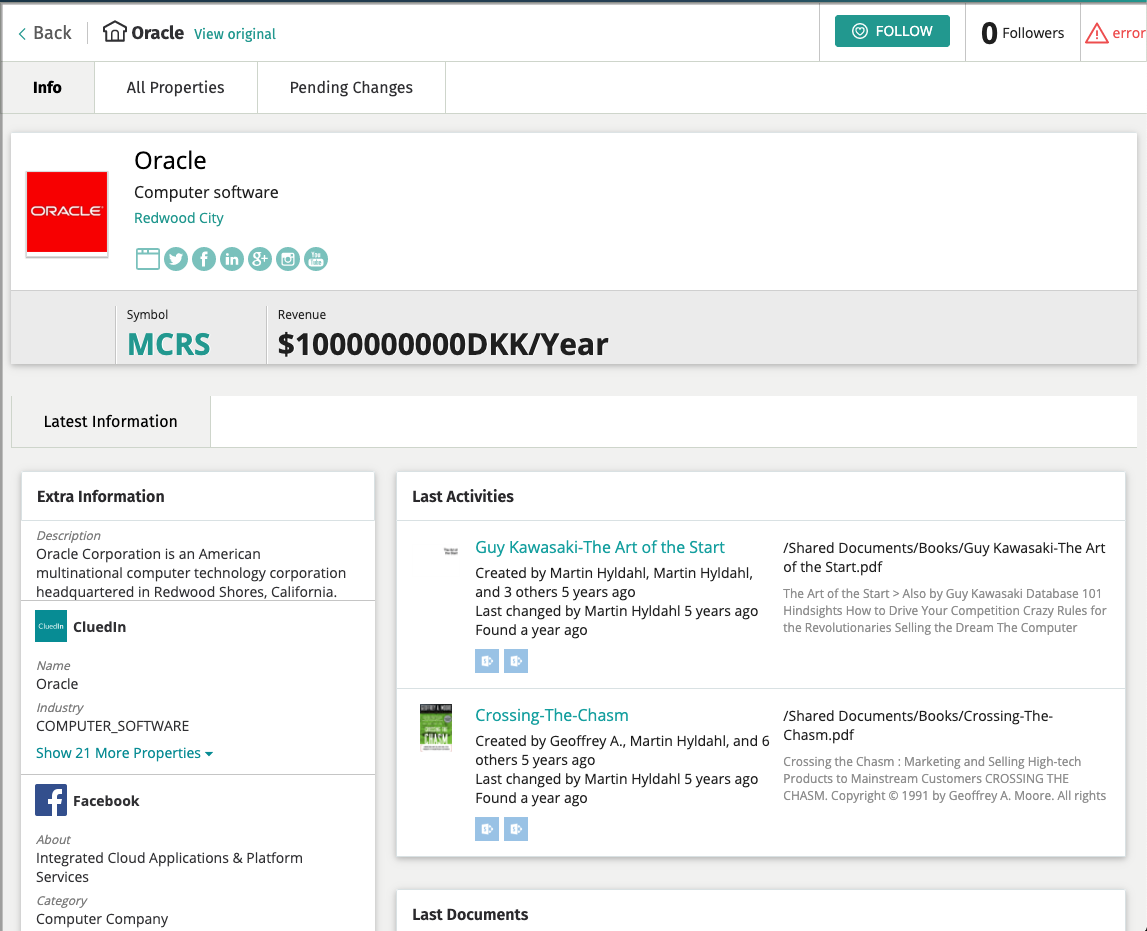
Here is thaat view after enrichment.
At the same time, you could imagine that if you looked up via something like the name of a company, you might actually receive multiple results back. The External Search framework of CluedIn can help solve this particular situation where we lookup via “fuzzy” reference as well as key identifier lookups as well.
To create a new provider, you will want to start by creating a new C# project and using Nuget to pull in the references to CluedIn.ExternalSearch as well as CluedIn.Core. From here you will want to create a new class and inherit from BaseExternalSearchProvider. Our External Search Providers are open source, so you might find it easier to simply learn from providers that have already been written.
Before we start coding, it is worth planning about what we will do to attack the project. An external search provider handles a few core pieces. Firstly, you will need to tell your new class what types of data you can lookup. This will typically be bound to a list of EntityTypes e.g. Organisation, Person. You can choose to have one External Search Provider per type or you can include many in the same provider - the choice is yours.
The next piece you will have to determine is what properties, core vocabularies and metadata you will need from the entities being passed to your new provider to properly lookup the external system. You might simply want to use the name of the entity, the display name or potentially some of the core or provider specific vocabularies. You might want to use the edges or aliases, the choice is really up to what your external provider can lookup values by.
The next planning step is to make the call to your provider using as filtered a value as possible. Obviously if we are looking up external services via a name, you might find that you receive hundreds of results. This is not a problem, it just means that more processing will happen on the CluedIn side to determine exactly which records to connect to your input from your external search queries. If you have the possibility and you have the data, it is best to add as many other filters onto your query instead of just the name of the record.
Finally you will need to map the results from your lookups back into Clues so that CluedIn can process this. The most critical piece to understand in this step is that your clues will need to have a perfect Entity Code match or you will need to map to core vocabularies that may or may not result in an Entity Code creation to an entity that already exists in your CluedIn account. All results from your external lookups will be natively stored in a local cache database to help in two main situations:
1: If we need to lookup that record again, we can look locally in this database first instead of constantly asking an external source for the same lookups and wasting API tokens. By default, this data clears its cache every 2 weeks. You can change this in your container.config file.
2: If a new Entity Code is created anywhere in CluedIn, then this local table may also contain Entity Codes that can now cause records to merge or link. You can explore this cache table by looking into the ExternalSearch table in your SQL datastore for CluedIn.
At this stage it is worth remembering that two clues or two entities will only merge if they have a perfect Entity Code match. This means that the Origin, Type and Id are exactly the same.
Considering that CluedIn comes out of the box with many different external search providers, you might find that by adding new external search providers, it will allow some of the other existing providers to have more possibilities of finding the right lookup records. This is due to the recursive nature of the External Search Provider framework.
If you find that you are looking up a service via an identifier like a domain or business Id, then chances are those records will bring back with it not only Entity Codes but also a value that will allow other External Search providers to lookup their own services. For example, imagine that we only had the Name, Domain and Twitter tag in CluedIn and then enabled the External Search providers. This might allow us to lookup Open Corporates via the company Name, Twitter using the Twitter tag and nothing using the Domain. We then might find that by looking up Twitter, the result will bring back a company logo, a company name and the phone number. This might mean that we can then lookup the White Pages or another business register via Phone Number and in-turn, that result might bring back the Facebook and LinkedIn Url and in-turn allow us to recursively lookup those respective External Search providers as well.
Many of these external search providers will require you to purchase API tokens as to use their API. This obviously means that we need to be aware of how many calls we use as to not run the bill up or process through this allowed token amount very quickly. It was mentioned above already that the cache table will help with this if you are looking up the exact same values and raising this cache limit to 4, 6 weeks or a larger capacity would help with this type of situation. It is also worth mentioning that we will only trigger another lookup to a service if a change is made to that record in CluedIn and the cache expiry on that individual record falls below the cache limit that you have set. At the same time, the more up-to-date you need your records, you might find that you lower this default 2 week cache to 2 days, or 2 hours.
Very similar to your integrations, you will need to construct a clue and use Vocabularies to be able to map back to core CluedIn vocabularies.
To enable a particular external search provider, you will need to change the respective “Enabled” flag in your container.config configuration file. By default, all are turned off in a new installation of CluedIn. This configuration file is also where we suggest that you place your appropriate API keys to talk to external providers that require it.
To be able to understand what lookup values an External Search provider supports and what types of Vocabularies it will enrich, you can call “api/integration/enricher/{id}/details” where id is the Id of the External Search Provider you are wanting to inspect.
Here is an example of what it will bring back for “Company House”:
[Id("2A9E52AE-425B-4351-8AF5-6D374E8CC1A5")]
[Name("Company House Enricher")]
[EnrichSource("www.companyhouse.com")]
[LookupEntityTypes("/Organization")]
[ReturnedEntityTypes("/Organization", "/Person")]
[LookupVocabularies("CluedIn.Core.Data.Vocabularies.Vocabularies.CluedInOrganization")]
[ReturnedVocabularies("CompanyHouseVocabulary.Organization", "CompanyHouseVocabulary.Person")]
[LookupVocabulariesKeys(
"CluedIn.Core.Data.Vocabularies.Vocabularies.CluedInOrganization.CodesCompanyHouse",
"CluedIn.Core.Data.Vocabularies.Vocabularies.CluedInOrganization.AddressCountryCode",
"CluedIn.Core.Data.Vocabularies.Vocabularies.CluedInOrganization.OrganizationName"
)
]
[ReturnedVocabulariesKeys(
"CompanyHouseVocabulary.Organization.CompanyNumber",
"CompanyHouseVocabulary.Organization.Charges",
"CompanyHouseVocabulary.Organization.CompanyStatus",
"CompanyHouseVocabulary.Organization.Type",
"CompanyHouseVocabulary.Organization.Jurisdiction",
"CompanyHouseVocabulary.Organization.Has_been_liquidated",
"CompanyHouseVocabulary.Organization.Has_insolvency_history",
"CompanyHouseVocabulary.Organization.Registered_office_is_in_dispute",
"CompanyHouseOrgAddressVocabulary.AddressLine1",
"CompanyHouseOrgAddressVocabulary.AddressLine2",
"CompanyHouseOrgAddressVocabulary.Locality",
"CompanyHouseOrgAddressVocabulary.PostCode",
"CompanyHouseVocabulary.Person.Name",
"CompanyHouseVocabulary.Person.Officer_role",
"CompanyHouseVocabulary.Person.Appointed_on",
"CompanyHouseVocabulary.Person.Date_of_birth",
"CompanyHouseVocabulary.Person.Country_of_residence",
"CompanyHouseVocabulary.Person.Occupation",
"CompanyHouseVocabulary.Person.Nationality",
"CompanyHouseVocabulary.Person.Resigned_on",
"CompanyHousePersonAddressVocabulary.CareOf",
"CompanyHousePersonAddressVocabulary.Region",
"CompanyHousePersonAddressVocabulary.Postal_code",
"CompanyHousePersonAddressVocabulary.Premises",
"CompanyHousePersonAddressVocabulary.Country",
"CompanyHousePersonAddressVocabulary.Locality",
"CompanyHousePersonAddressVocabulary.AddressLine1",
"CompanyHousePersonAddressVocabulary.AddressLine2"
)
]