Process data
On this page
In this article, you will learn about the processing of data that you ingested into CluedIn. The goal of processing is to turn your records into standalone golden records or to use them to enhance existing golden records.
Depending on the type of data source, there are three processing options:
-
For file, ingestion endpoint, and database: Manual processing
-
For ingestion endpoint only: Auto-submission
-
For ingestion endpoint only: Bridge mode
You can process the data set as many times as you want. In CluedIn, once a record has been processed, it won’t undergo processing again. When the processing is started, CluedIn checks for identical records. If identical records are found, they won’t be processed again. However, if you change the primary identifier for the previously processed records, CluedIn will treat these records as new and process them.
After processing is completed, the following takes place:
-
Processing log appears in the table.
-
Records are moved to quarantine if:
-
They fail to meet specific conditions outlined in property or pre-process rules. will be sent to quarantine.
-
(For data ingested through an endpoint) Schema protection is enabled, and the records contain fields outside of the defined mapping.
-
-
Records that were processed successfully are displayed on the Data tab.
If the processing takes a long time, go to the Monitoring tab and check the number of messages in the queues. Depending on the type of message queue with a high message count, you can perform specific troubleshooting actions. For further details, see Monitoring.
Manual processing
Manual processing is available for the data coming from a file, an ingestion endpoint, or a database. With manual processing, the original data that was initially sent to CluedIn remains in the temporary storage on the Preview tab. After the data has been processed, the resulting golden records appear on the Data tab.
To process the data
-
On the navigation pane, go to Integrations > Data Sources. Then, find and open the data set that you need to process.
-
Go to the Process tab, and then select Process.
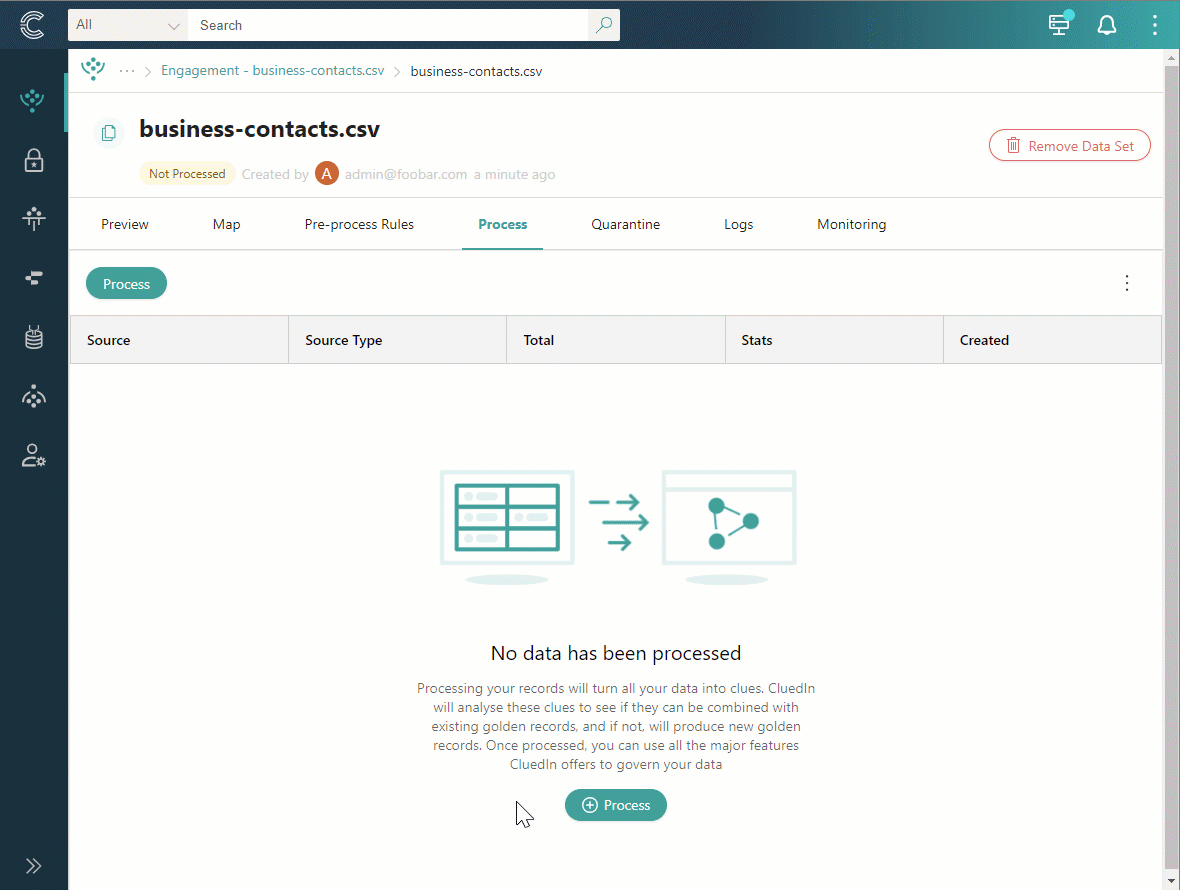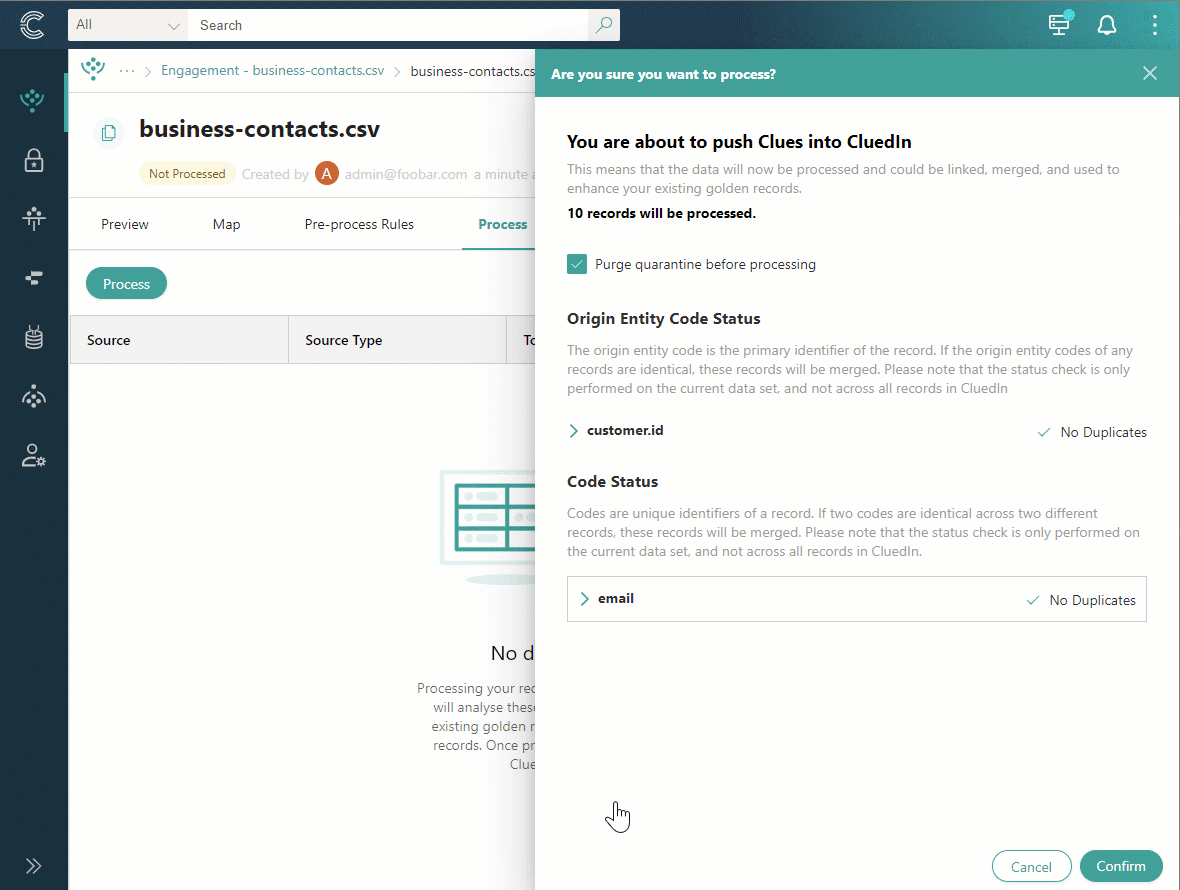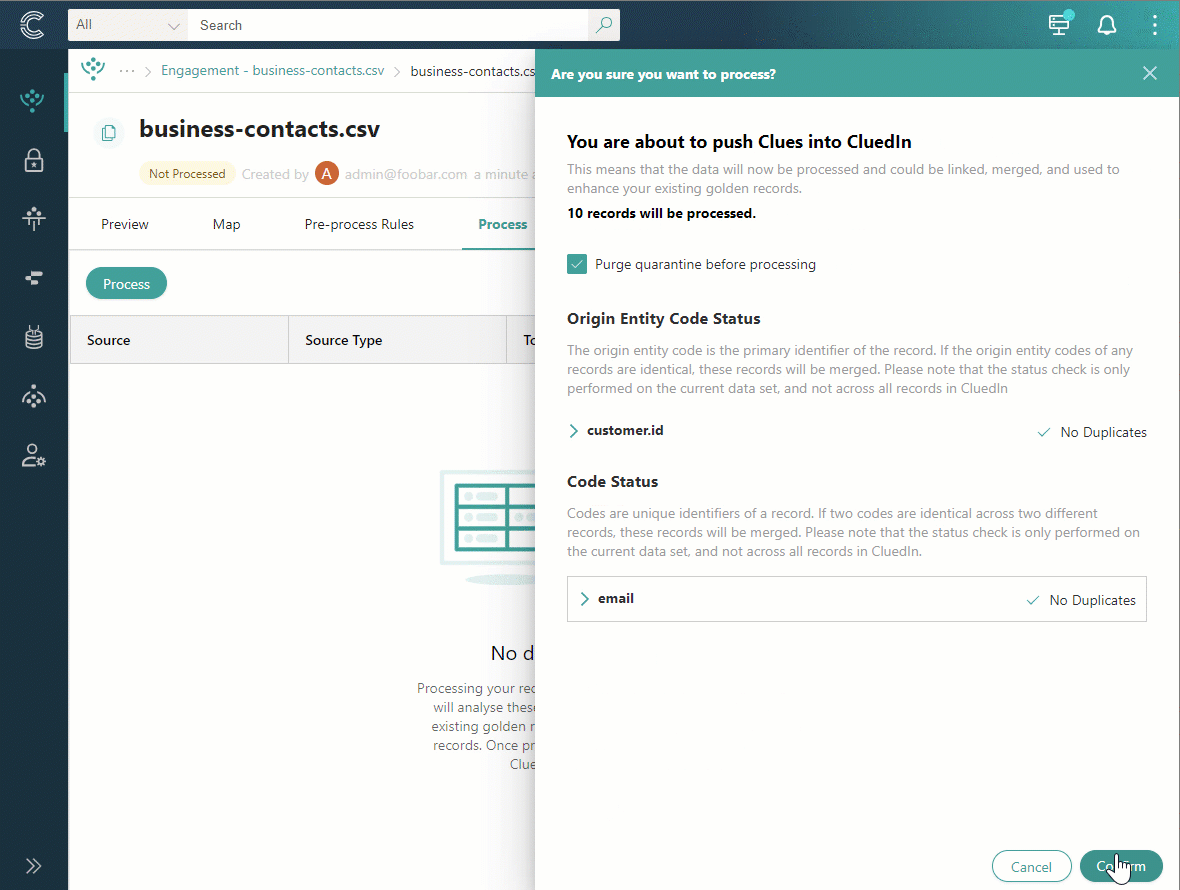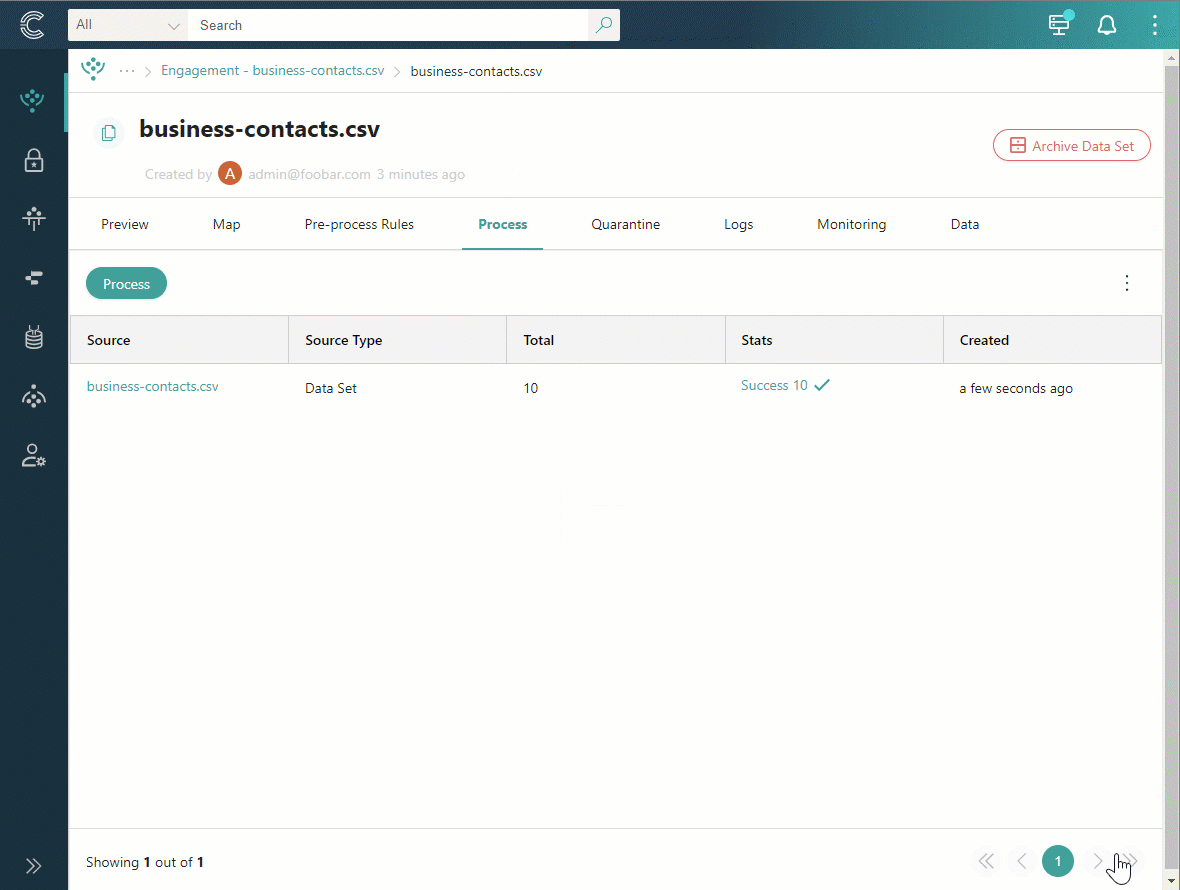
The confirmation pane opens, where you can do the following:
-
View the number of records that will be processed.
-
Delete the records that are currently in quarantine. This option is useful if you have already processed the data set before and there are some records in quarantine.
-
View the result of the primary identifier status check along with the field that was selected for producing the primary identifier.
-
View the result of the identifier status check along with the field that was selected for producing additional identifier.
If any status check shows duplicates, the records containing duplicates will be merged to maintain data integrity and consistency. To learn more about unique identifiers, see Identifiers.
-
-
In the lower-right corner, select Confirm.
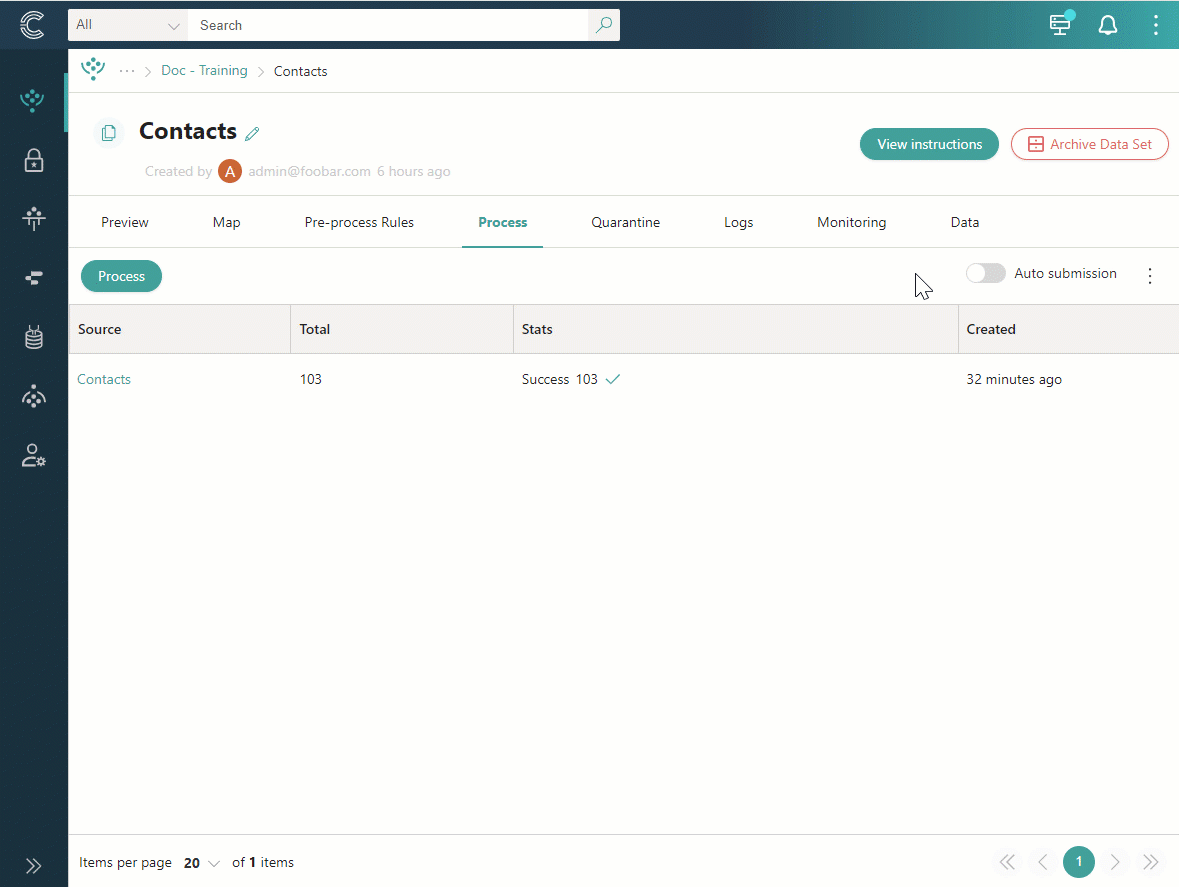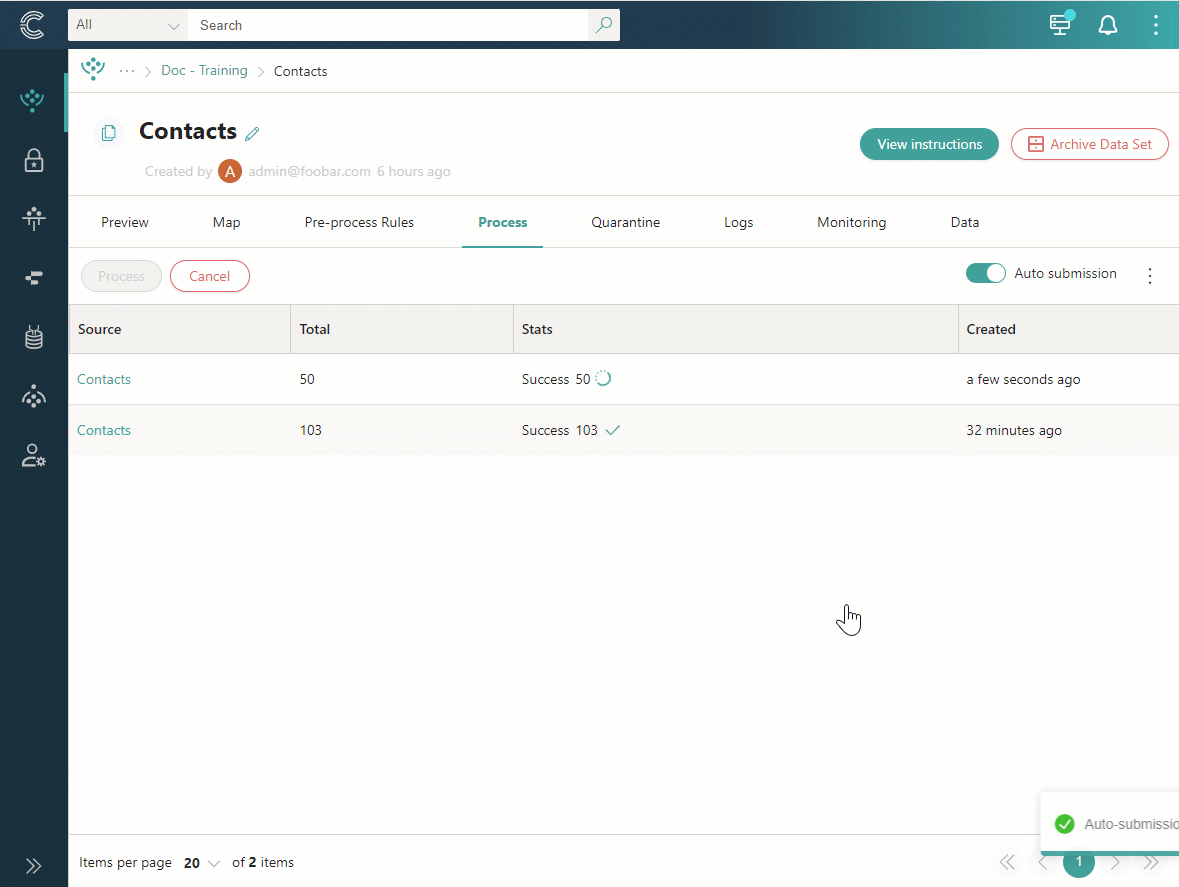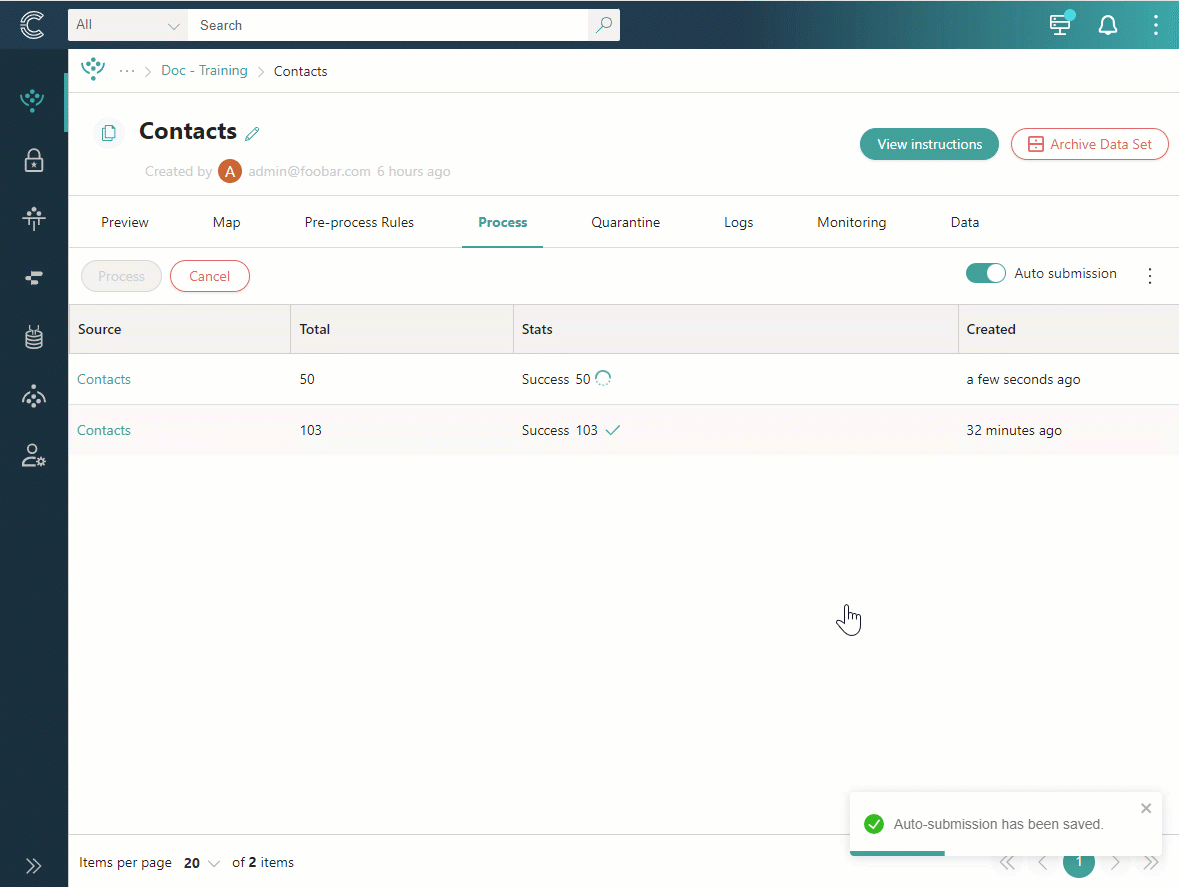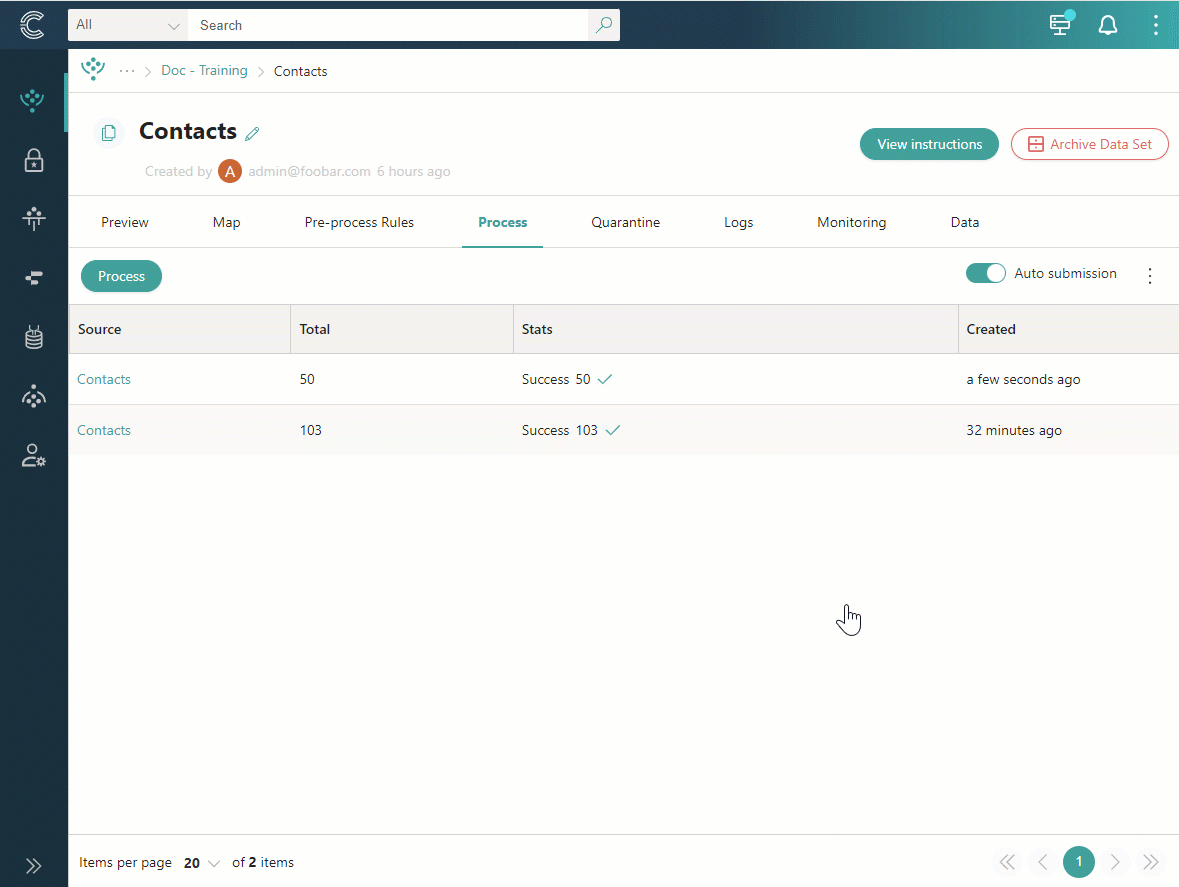
Auto-submission
Auto-submission is available for the data coming from an ingestion endpoint. When auto-submission is enabled, data received from the ingestion endpoint is processed automatically. With auto-submission, the original data that was initially sent to CluedIn remains in the temporary storage on the Preview tab. After the data has been processed, the resulting golden records appear on the Data tab.
To enable auto-submission
-
On the navigation pane, go to Integrations > Data Sources. Then, find and open the data set for which you want to enable auto-submission.
-
Go to the Process tab, and then turn on the toggle next to Auto-submission.
-
Confirm that you want to enable automatic processing of records once they are received by CluedIn.
If you no longer want the records to be processed automatically, turn off the toggle next to Auto-submission.
Bridge mode
Bridge mode is available for the data coming from an ingestion endpoint. When bridge-mode is enabled, all your JSON records will be transformed into golden records directly, without being stored in the temporary storage on the Preview tab. However, you can rely on data set logs and ingestion receipts for debugging purposes.
Bridge mode allows you to use less storage and memory, resulting in increased performance. Use this mode when your mapping will not change over time, and you want to use the ingestion endpoint only as a mapper.
To switch to bridge mode
-
On the navigation pane, go to Integrations > Data Sources. Then, find and open the data set that you want to switch to bridge mode.
-
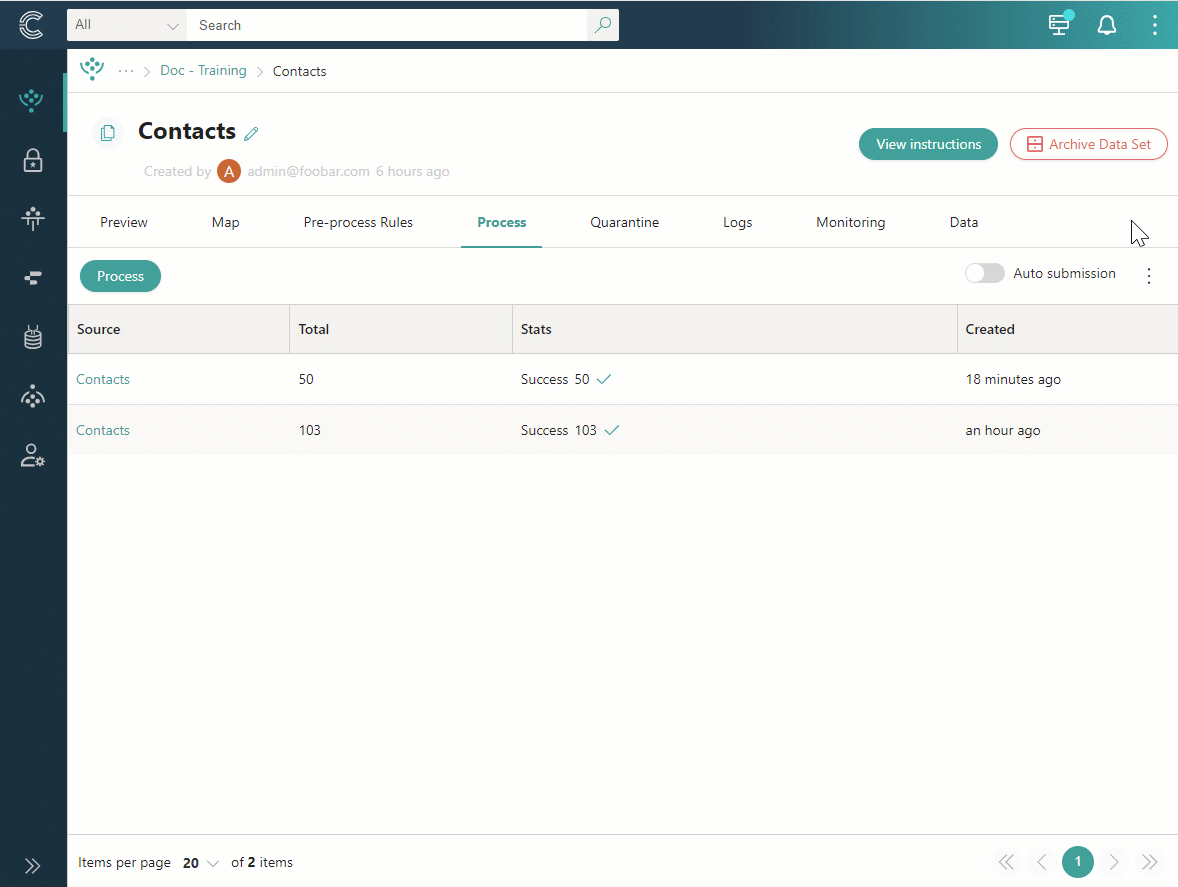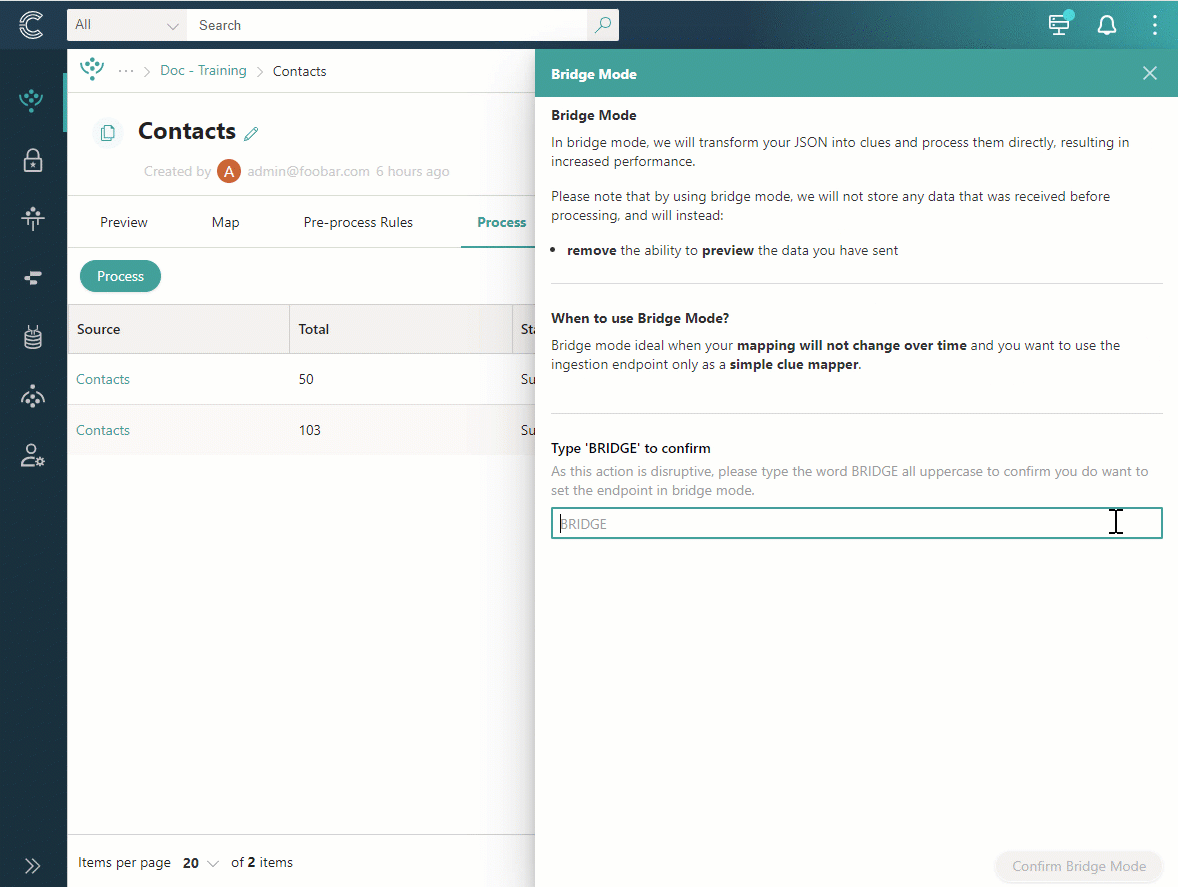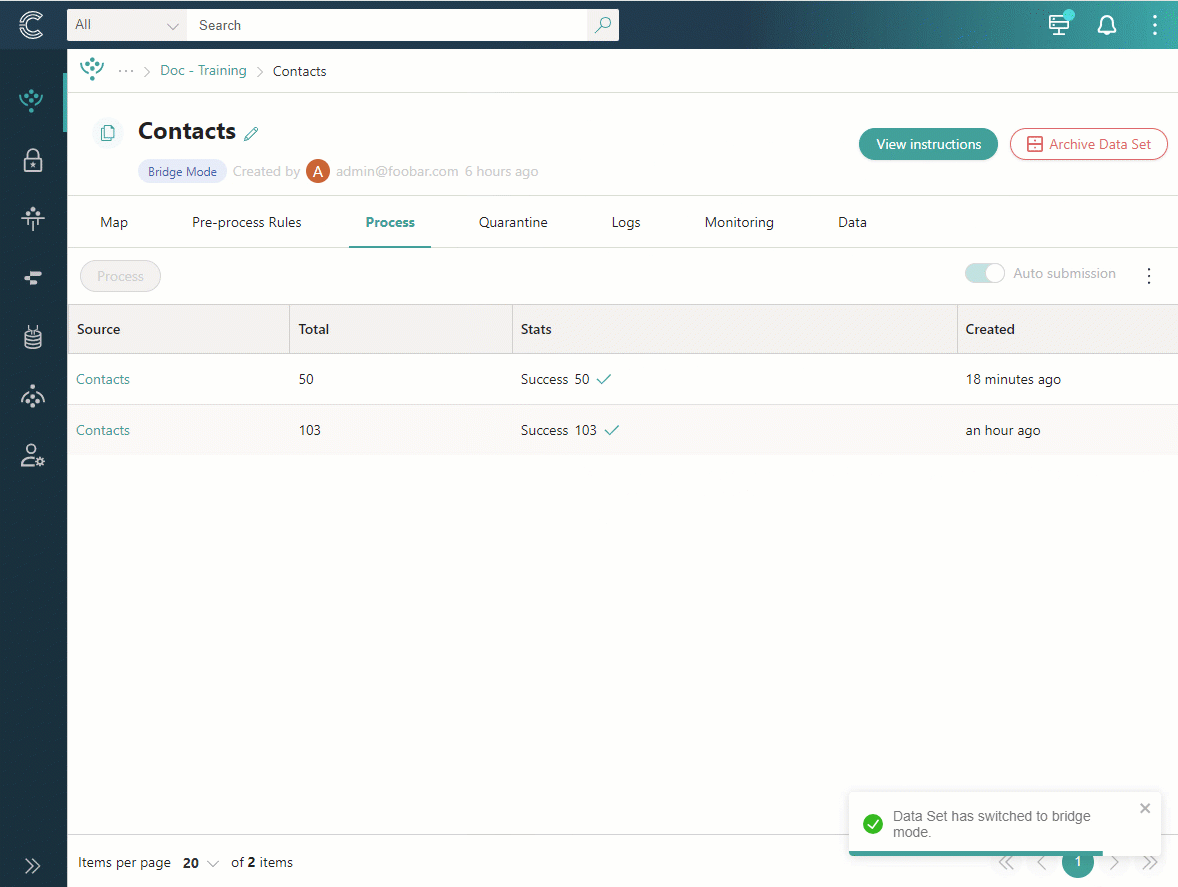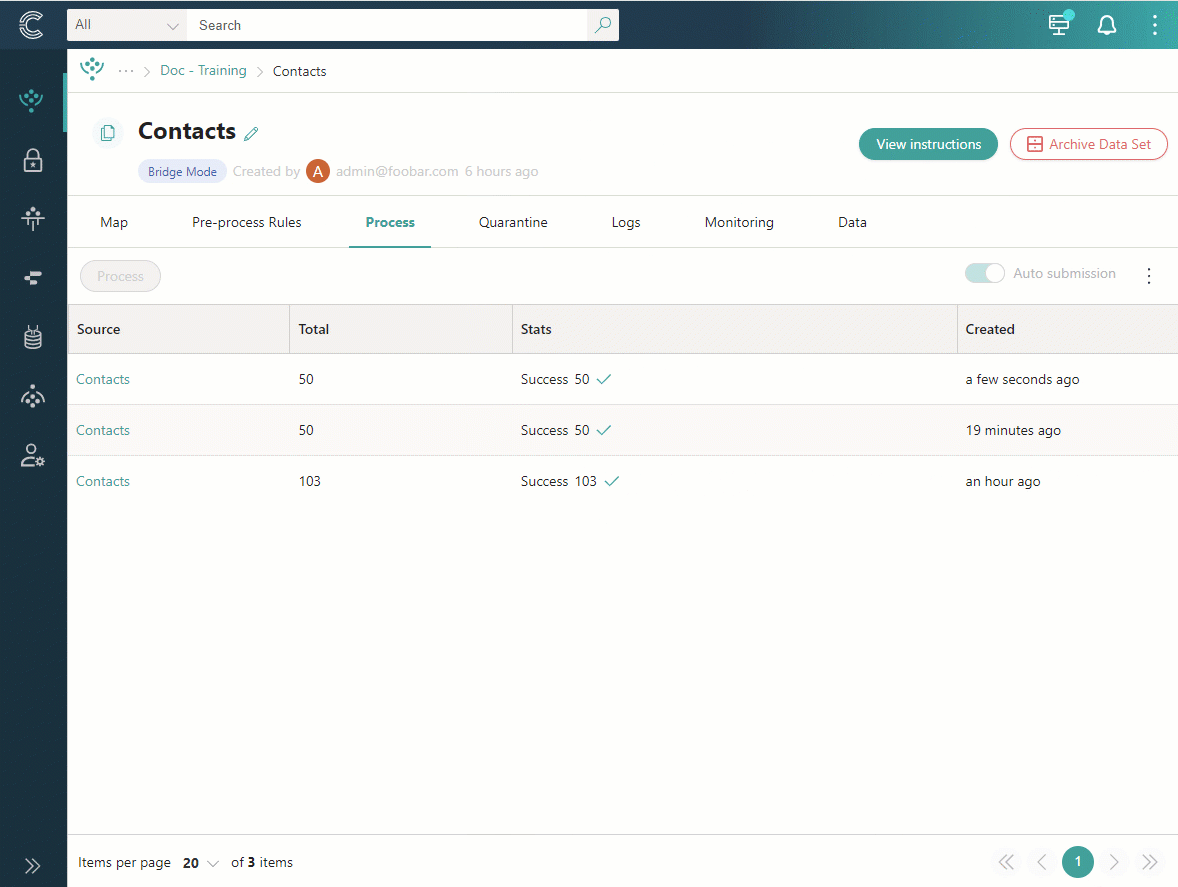
Go to the Process tab. Open the three dots menu, and then select Switch to bridge mode.
-
Confirm that you want to switch to bridge mode by entering BRIDGE. Then, select Confirm bridge mode.
If you no longer want your ingestion endpoint to operate in bridge mode, you can switch it back to the default mode. After switching back to the default mode, the Preview tab will appear. However, it will not contain records received while bridge mode was enabled.
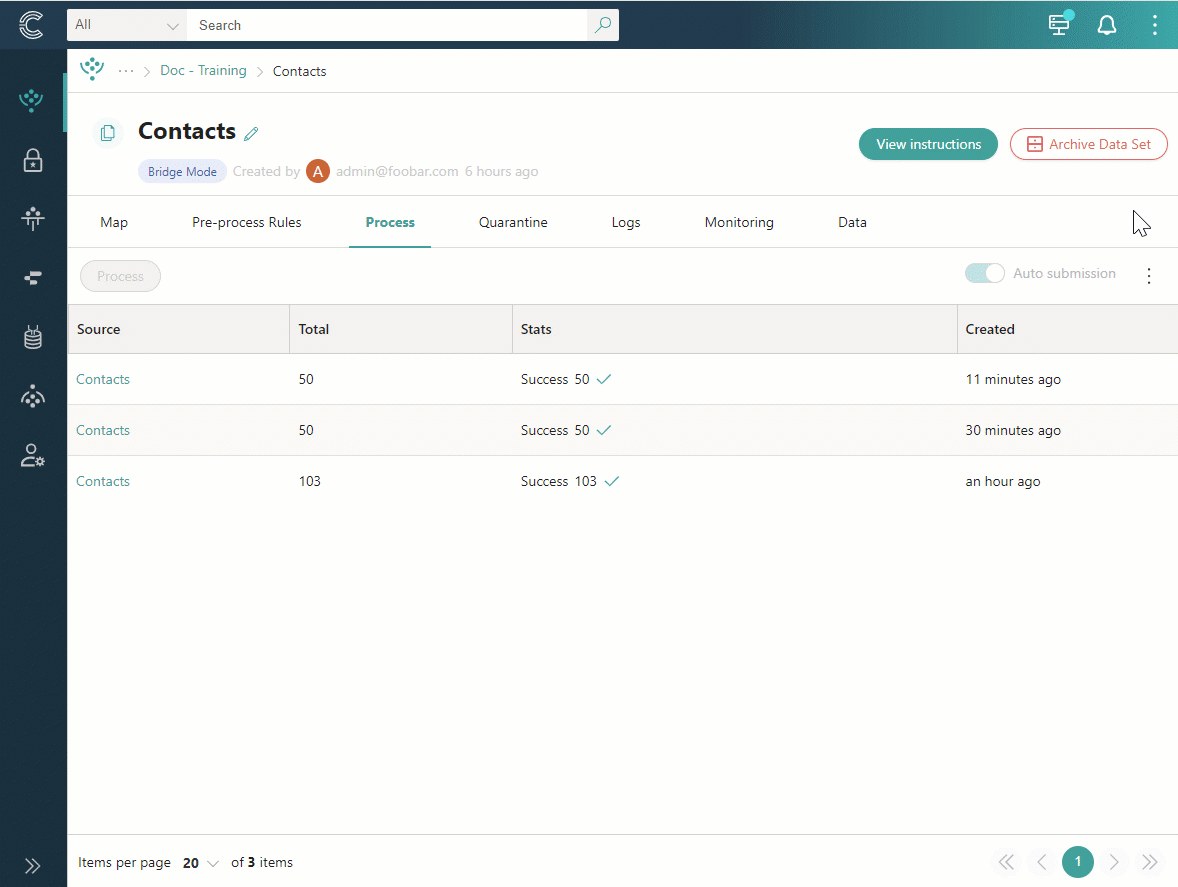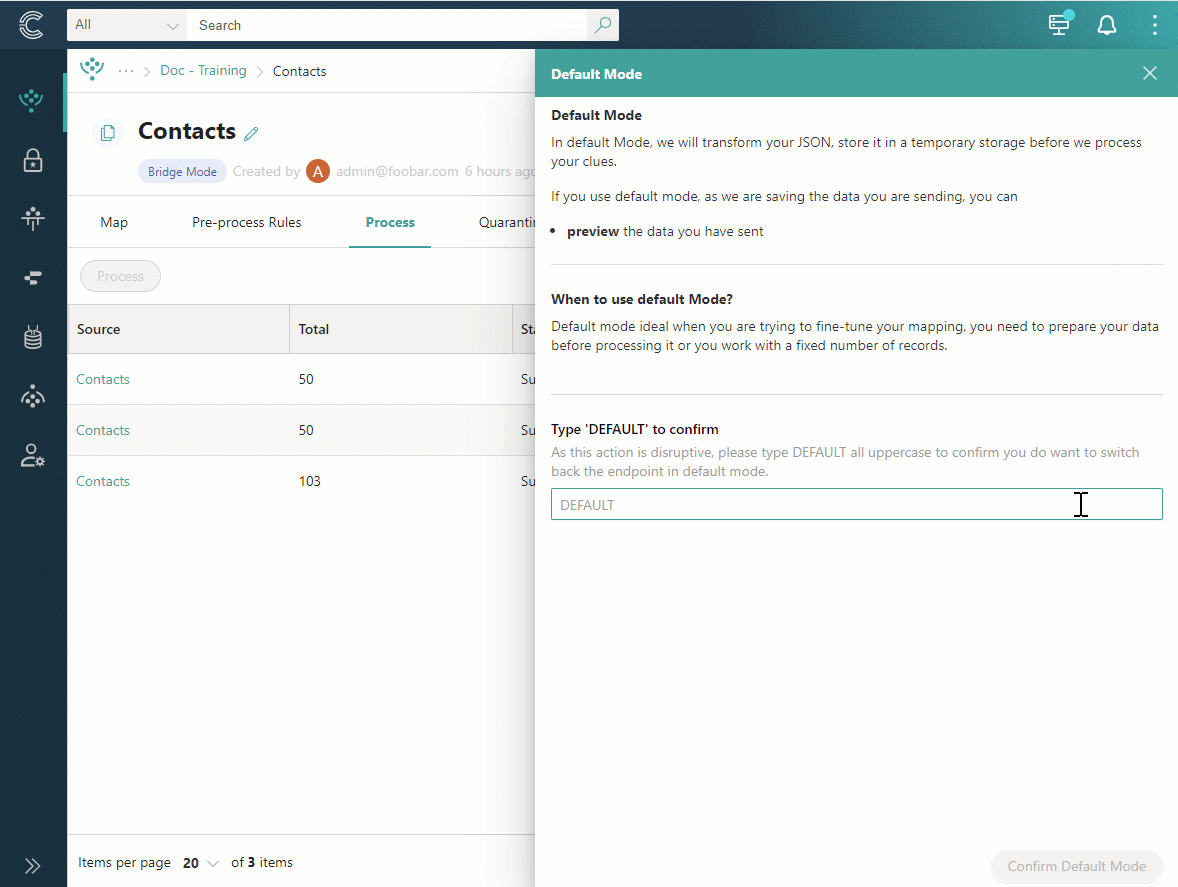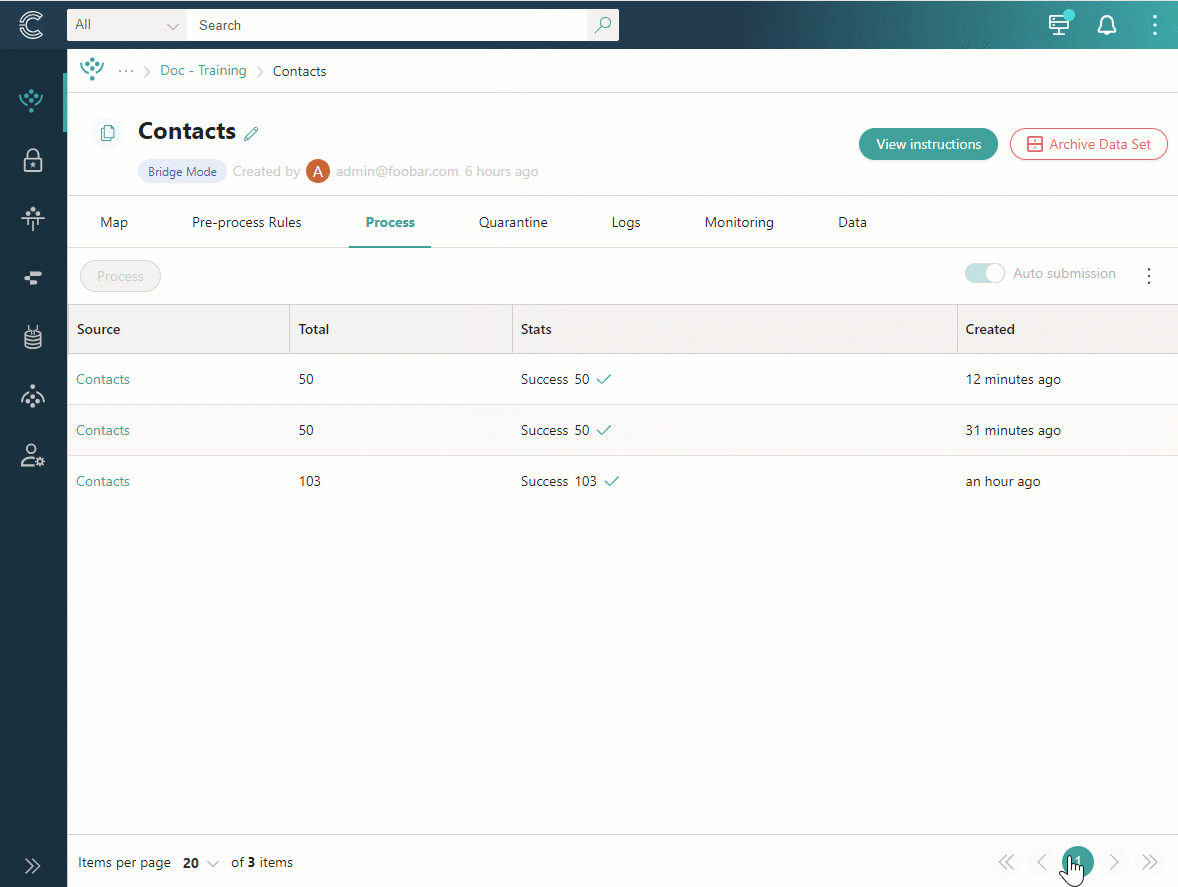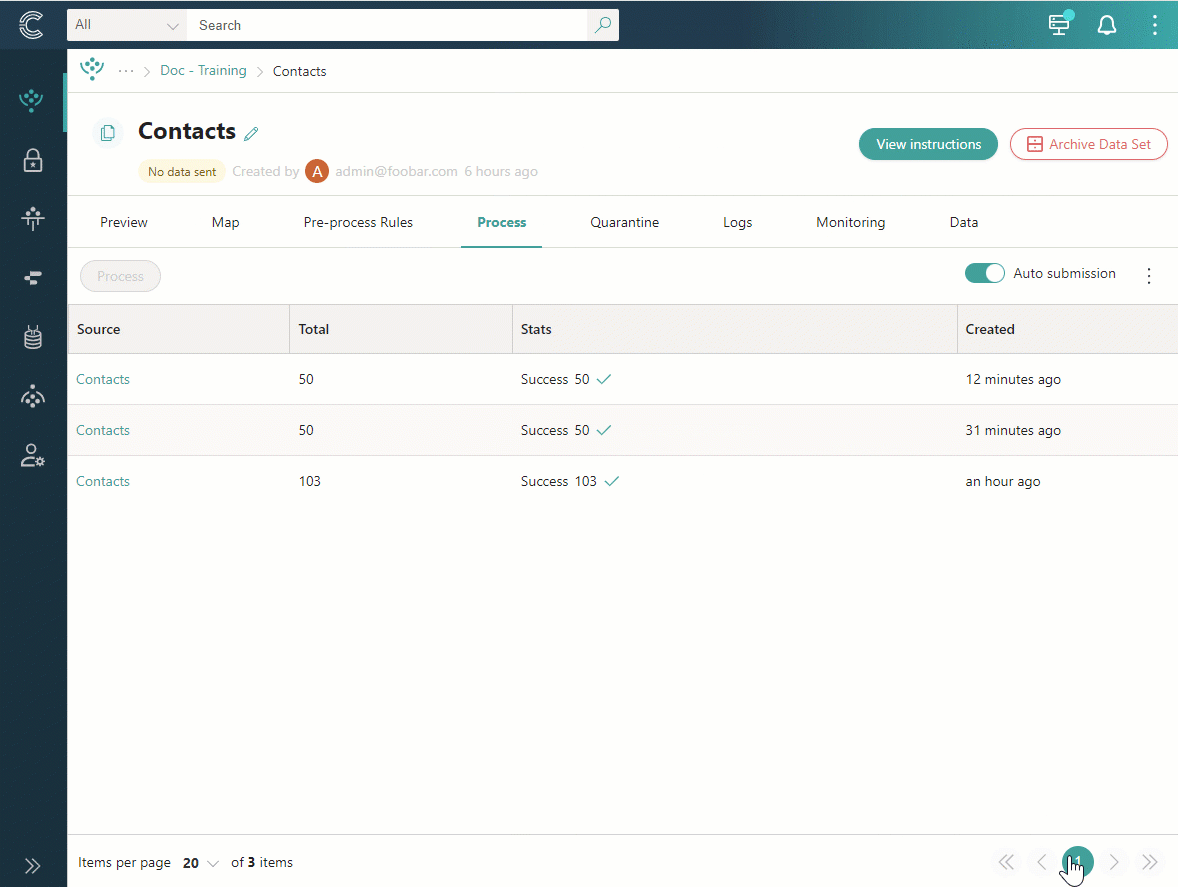
To switch back to default mode
-
On the navigation pane, go to Integrations > Data Sources. Then, find and open the data set that you want to switch back to default mode.
-
Go to the Process tab. Open the three dots menu, and then select Switch to default mode.
-
Confirm that you want to switch back to default mode by entering DEFAULT. Then, select Confirm default mode.
Processing logs
Every time the records are processed, a new processing log appears on the Process tab of the data set. If the number of processing logs is growing, consider removing older logs. You can also configure the retention settings to automatically remove processing logs after a specific period.
Remove processing logs
Removing processing logs frees up disk space without impacting the processed records. However, once removed, processing logs cannot be recovered.
To remove processing logs
-
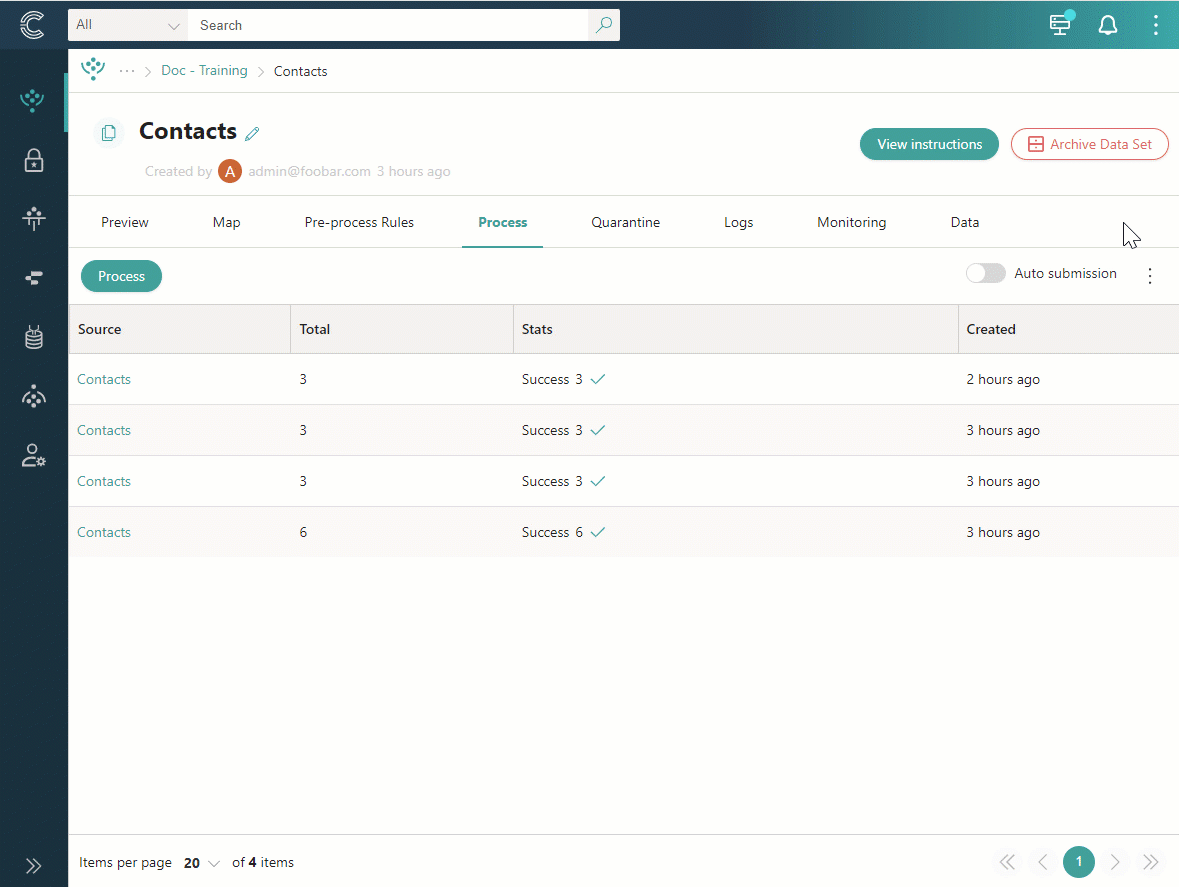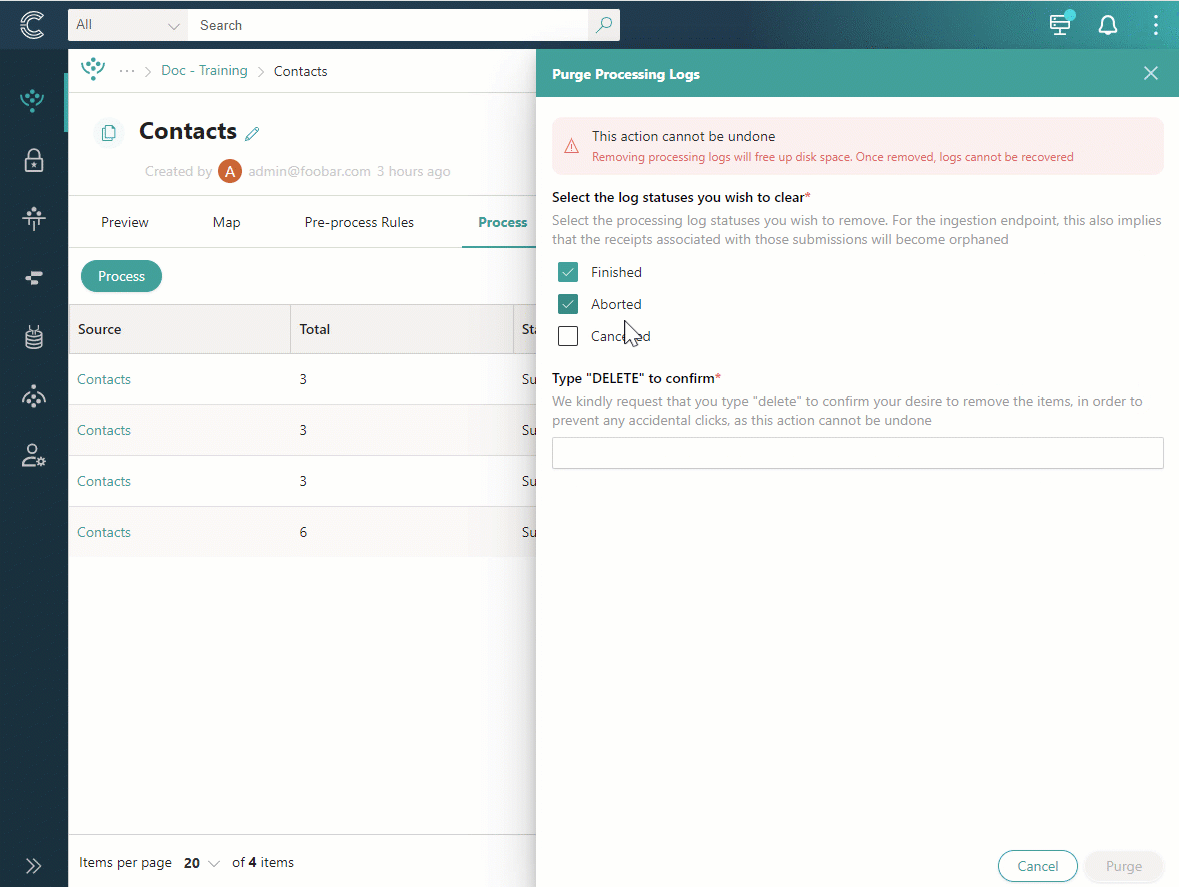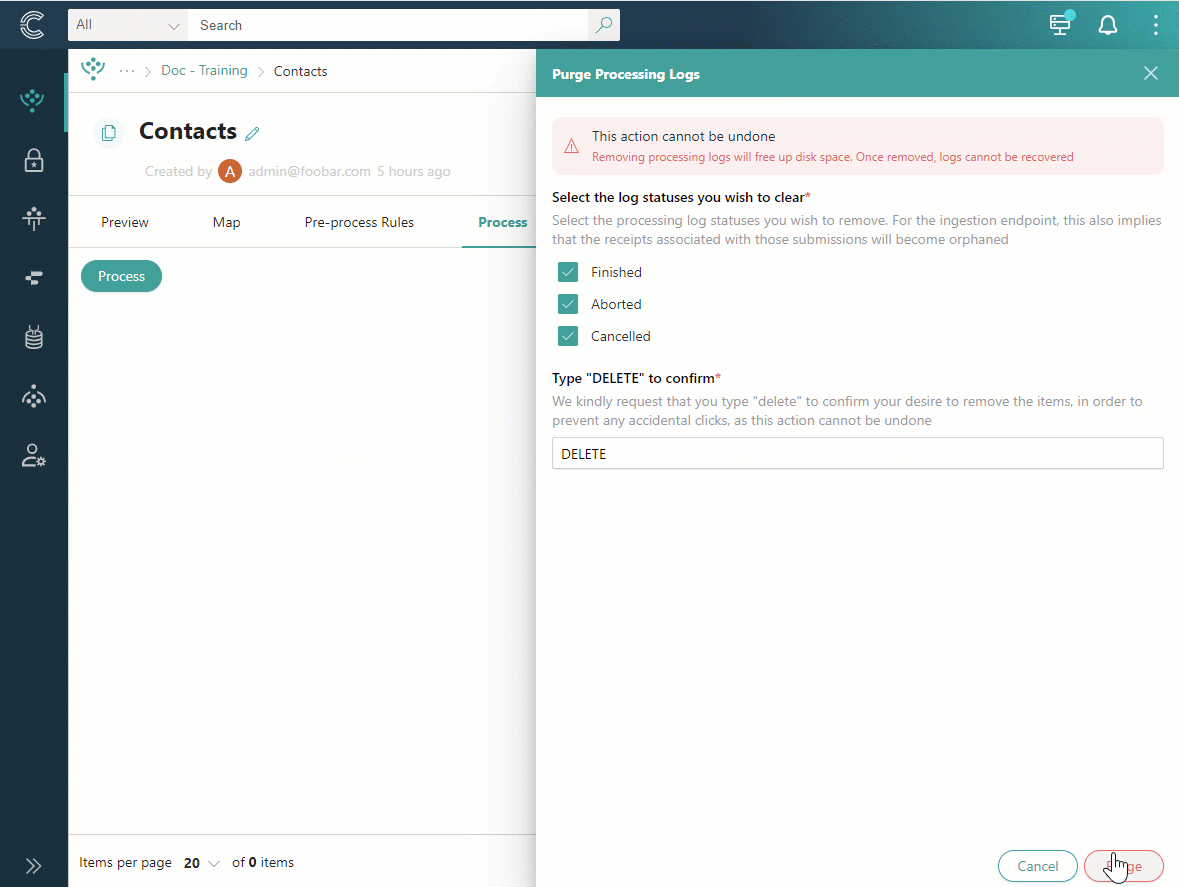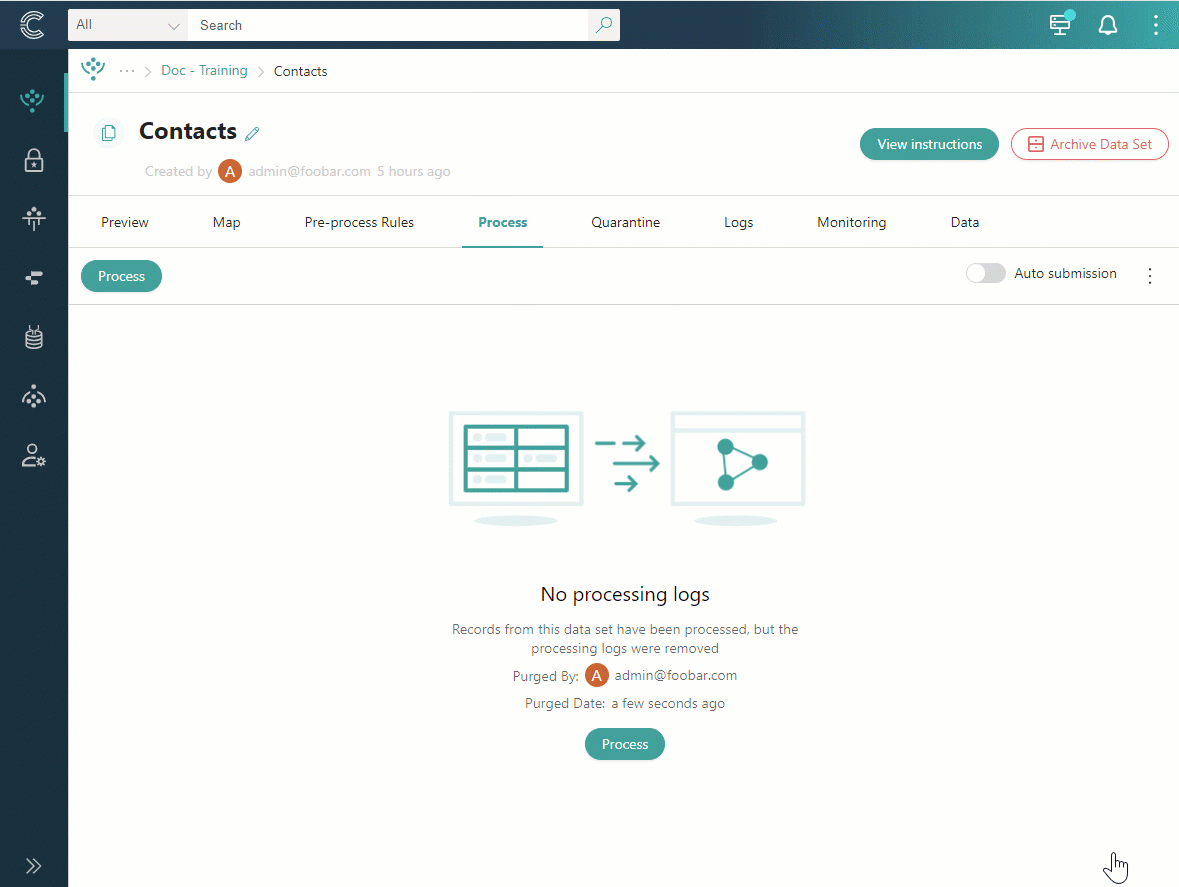
Near the upper-right corner of the processing logs table, open the three dots menu, and then select Purge processing logs.
-
Select the statuses of the processing logs that you want to remove.
-
Confirm that you want to remove processing logs by entering DELETE. Then, select Purge.
After processing logs are removed, the Process tab will display information about the user who removed them and the time of removal.
Configure retention settings
Retention settings allow you to automatically delete processing logs after a specified period.
To configure retention settings
-
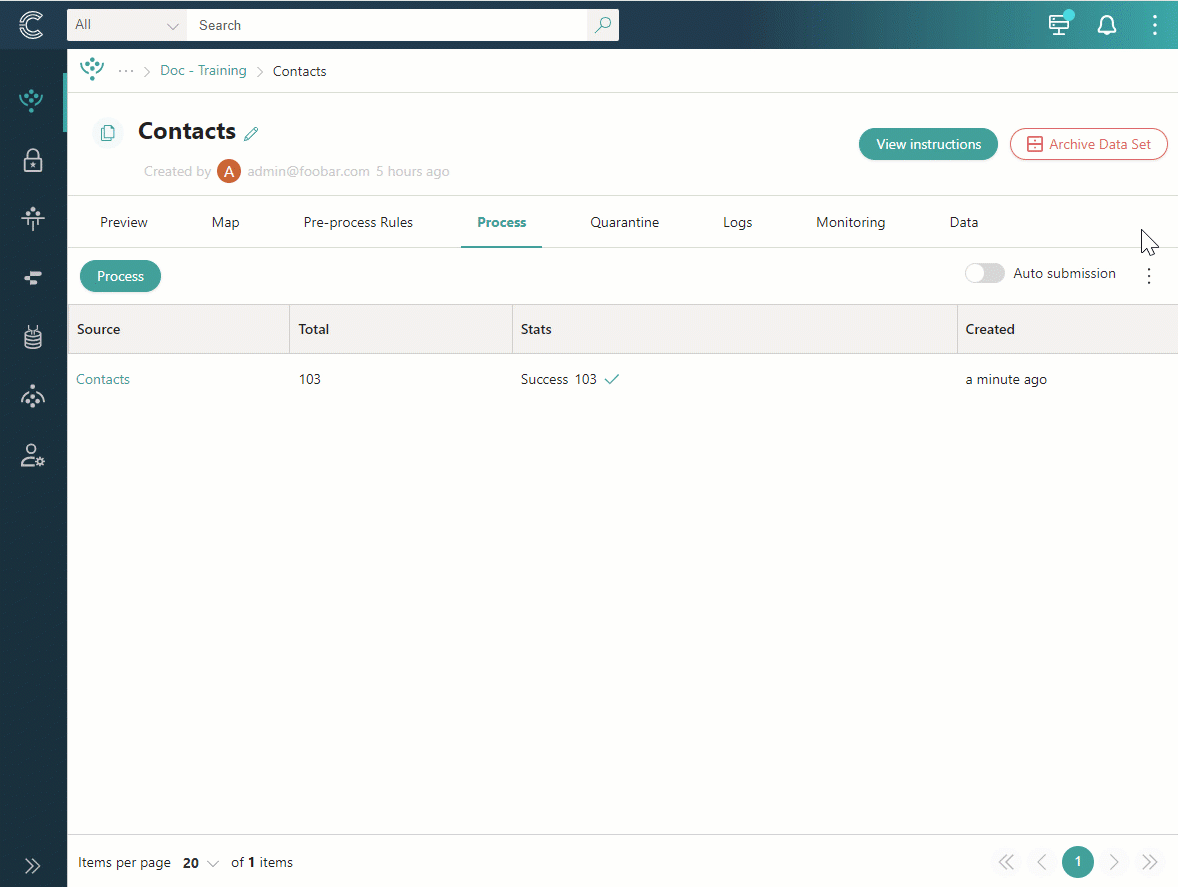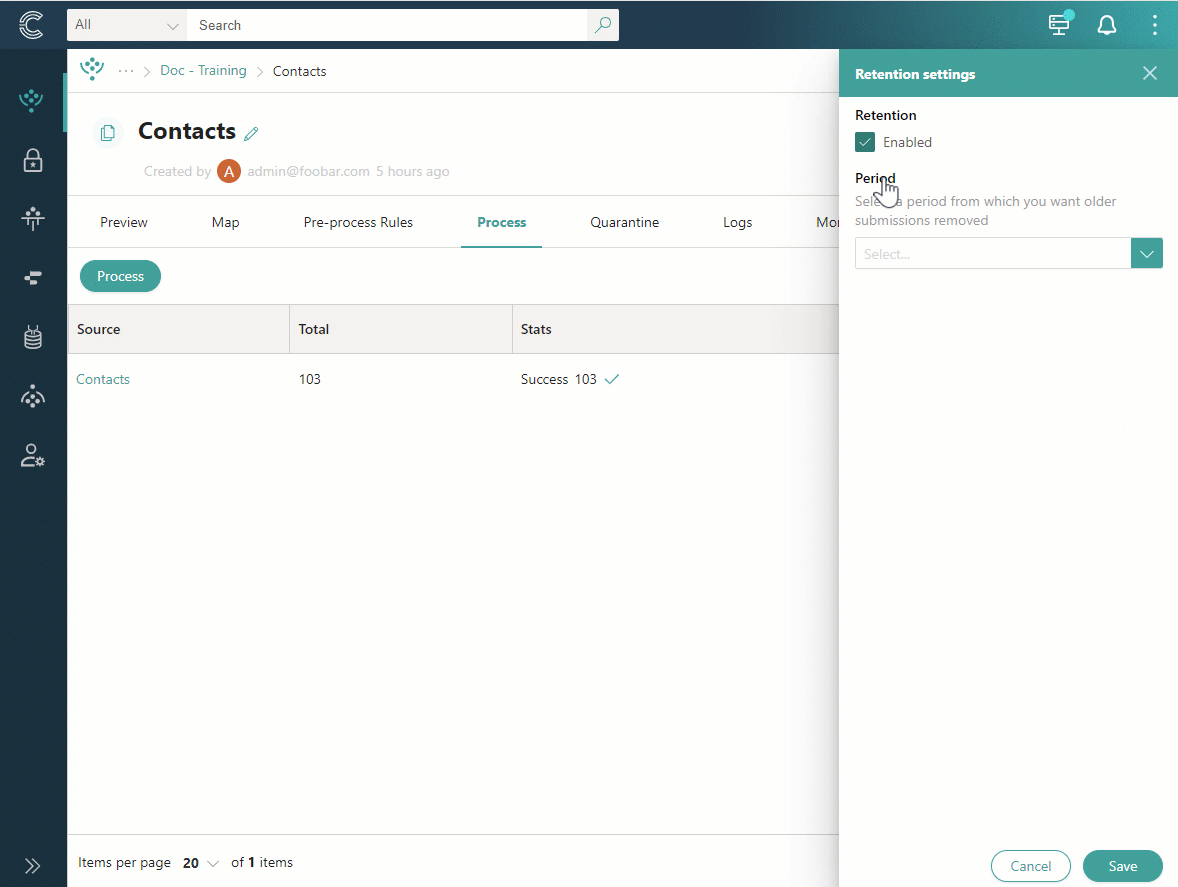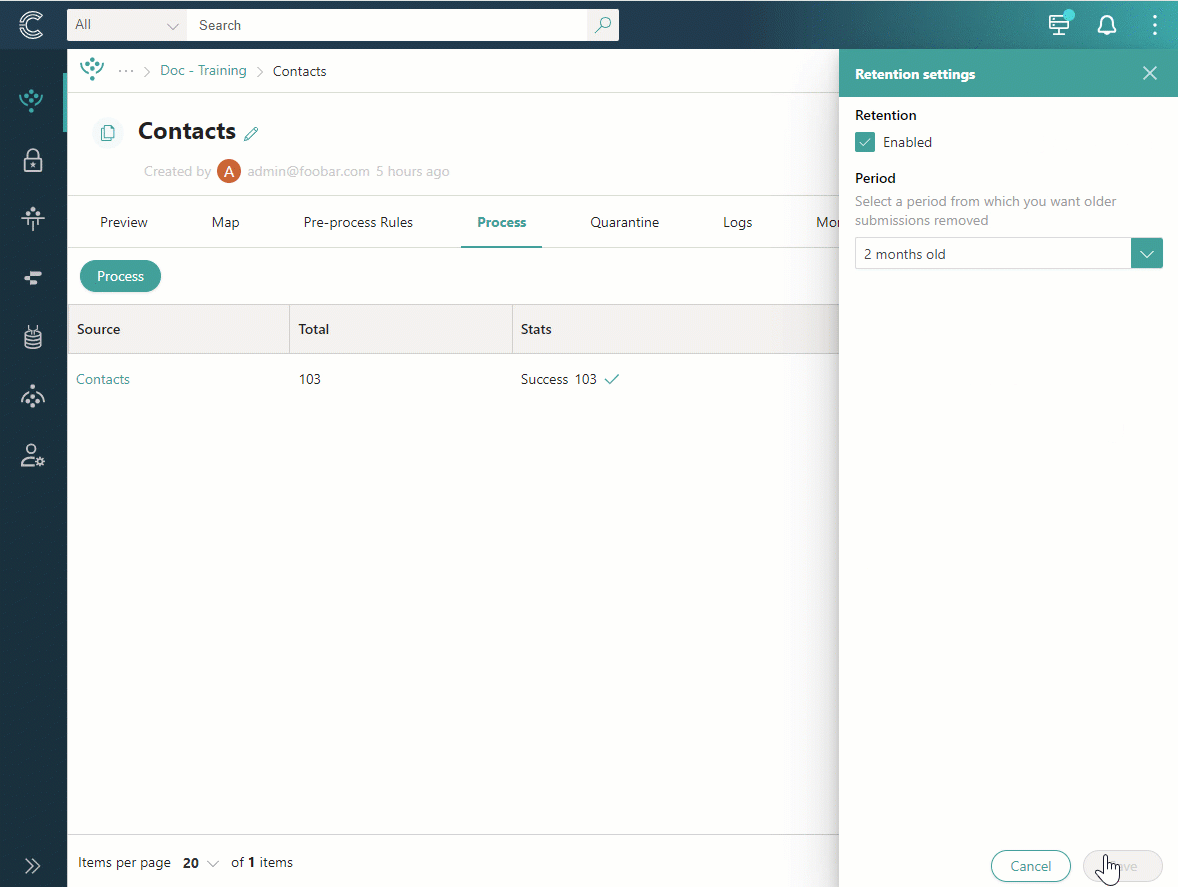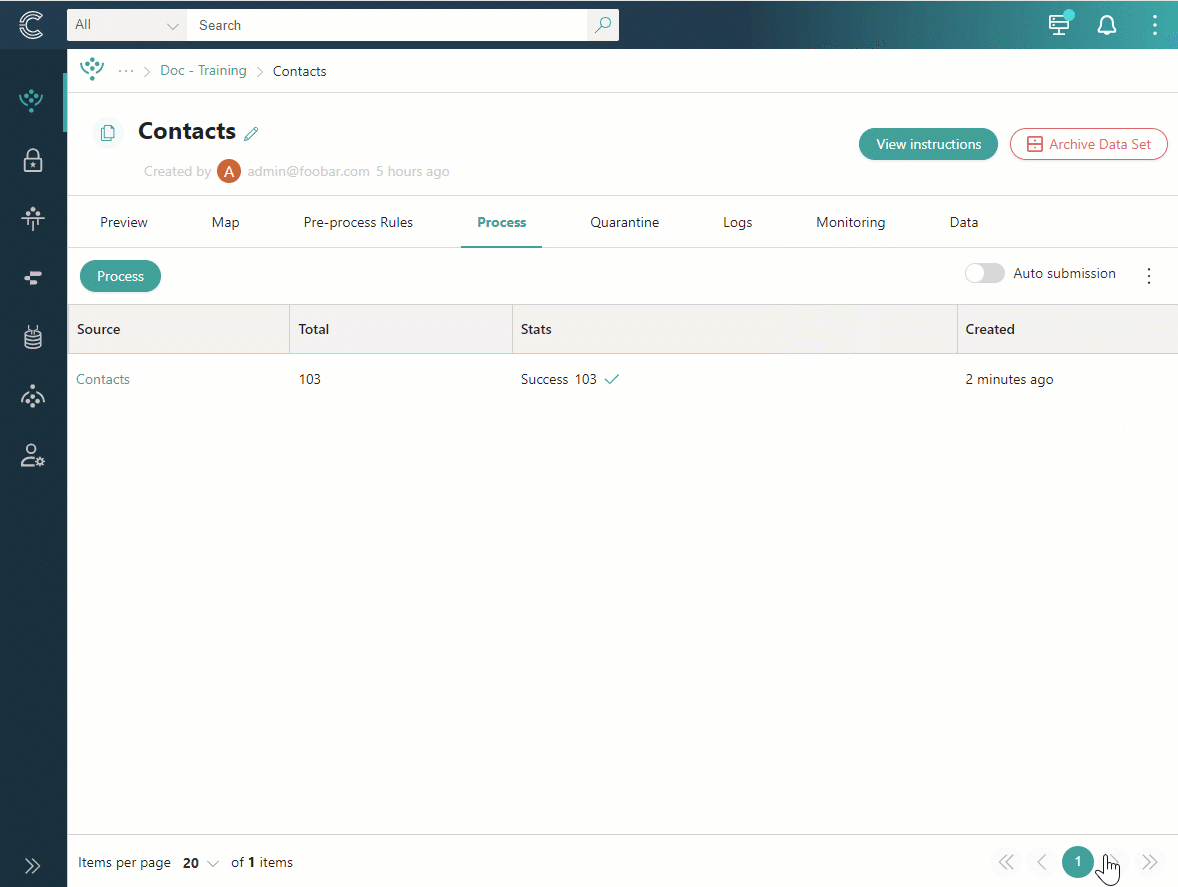
Near the upper-right corner of the processing logs table, open the three dots menu, and then select Retention settings.
-
Select the checkbox to enable retention.
-
Select a period to specify which processing logs should be removed. For example, selecting 2 months old means that all processing logs created 2 months ago will be removed. Thus, when a processing log turns 2 months old, it will be automatically removed.
-
Select Save.
-
If you want to change the retention period, repeat step 1. Then, select another period and save your changes.
-
If you want to remove the retention settings, repeat step 1. Then, clear the checkbox to disable retention and save your changes.