Use CluedIn rules in Microsoft Fabric
On this page
- Set up your environment
- Retrieve rules from CluedIn
- Evaluate data against rule conditions
- Apply rule actions to your data
- Work with CluedIn data in Microsoft Fabric
- Filter data with evaluators
CluedIn provides a powerful GraphQL API for retrieving data and metadata and executing actions. In this article, you will learn how to read CluedIn rules’ metadata in Microsoft Fabric and use it to work with data in OneLake.
Set up your environment
Create a notebook in Microsoft Fabric, install dependencies, and get a CluedIn access token:
!pip install cluedin
!pip install jqqb_evaluator
import cluedin
ctx = cluedin.Context.from_dict({
"domain": "cluedin.demo",
"org_name": "foobar",
"user_email": "admin@cluedin.demo",
"user_password": "yourStrong(!)Password"
})
ctx.get_token()
Retrieve rules from CluedIn
Get all the rules from CluedIn:
# get all data part rules
rules = cluedin.rules.get_rules(ctx)
# output rule names
list(map(lambda x: x['name'], rules['data']['management']['rules']['data']))
Retrieve a specific rule by ID:
cluedin.rules.get_rule(ctx, rule_id)
Evaluate data against rule conditions
You can create an Evaluator to check if a given object matches the rule’s conditions. In the following example, we take all data part rules from CluedIn, create a list of evaluators, and then check if a test object matches at least one evaluator in the list:
# get all data part rules ids
rule_ids = list(map(lambda x: x['id'], cluedin.rules.get_rules(ctx)['data']['management']['rules']['data']))
# get full rule data
rules = list(map(lambda rule_id: cluedin.rules.get_rule(ctx, rule_id), rule_ids))
# get a list of evaluators for all rules
evaluators = list(map(lambda rule: cluedin.rules.Evaluator(rule['data']['management']['rule']['condition']), rules))
# test object
obj = {
'employee.job': 'Akkounting'
}
# returns True if the object matches to at least one evaluator in the list
any(map(lambda evaluator: evaluator.object_matches_rules(obj), evaluators))
Use the explain() method to understand how evaluators check conditions. It outputs code in terms of pandas’ DataFrame.query method:
# explain all evaluators
list(map(lambda evaluator: evaluator.explain(), evaluators))
Sample output:
[
'df.query(\'`employee.job` == "Ackounting" | `employee.job` == "Acounting" | `employee.job` == "Akkounting" | `employee.job` == "aCoUnTiNg" | `employee.job` == "account ing" | `employee.job` == "accounting"\')',
'df.query(\'`employee.job` == "Software Dev"\')',
'df.query(\'`employee.job` == "Softwear Dev"\')'
]
Apply rule actions to your data
Define helper functions to interpret and apply CluedIn rule actions:
def set_value_action(obj, field, val):
"""
Set Value action: takes an object (obj), and sets its property (field) to a value (val).
"""
obj[field] = val
return obj
def get_action(action_json):
"""
Takes a Rule Action JSON, and returns a lambda
"""
if action_json['type'] == 'CluedIn.Rules.Actions.SetValue, CluedIn.Rules':
field = None
val = None
for prop in action_json['properties']:
if prop['name'] == 'FieldName':
field = prop['value']
elif prop['name'] == 'Value':
val = prop['value']
return lambda obj: set_value_action(obj, field, val)
print(f'Action "{action_json["type"]}" is not supported. Object:', obj)
return lambda obj: obj
def get_actions_with_evaluators(rule):
"""
For a given rule, returns an iterable of objects containing an action and a corresponding evaluator:
{
'action': lambda x: ...,
'evaluator': ...
}
"""
for r in rule['data']['management']['rule']['rules']:
for a in r['actions']:
yield {
'evaluator': cluedin.rules.Evaluator(rule['data']['management']['rule']['condition']),
'action': get_action(a)
}
# test action (not evaluator)
result = list(get_actions_with_evaluators(rules[0]))
result[0]['action']({ 'employee.job': 'CEO' })
Apply actions conditionally:
def apply_actions(actions_with_evaluators, obj):
"""
Given a list of actions with evaluators pairs and an object (obj),
apply action to the object if it passes the corresponding evaluator.
"""
for action_with_evaluator in actions_with_evaluators:
if action_with_evaluator['evaluator'].object_matches_rules(obj):
obj = action_with_evaluator['action'](obj)
return obj
# test
actions_with_evaluators = [action_with_evaluator for rule in rules for action_with_evaluator in get_actions_with_evaluators(rule)]
apply_actions(actions_with_evaluators, { 'employee.job': 'Akkounting' })
Work with CluedIn data in Microsoft Fabric
Load CluedIn data into a DataFrame:
import pandas as pd
query = """
query searchEntities($cursor: PagingCursor, $query: String, $pageSize: Int) {
search(
query: $query
sort: FIELDS
cursor: $cursor
pageSize: $pageSize
sortFields: {field: "id", direction: ASCENDING}
) {
cursor
entries {
id
entityType
properties
}
}
}
"""
df = pd.DataFrame(cluedin.gql.entries(ctx, query, { 'query': 'entityType:/Employee', 'pageSize': 10_000 }, flat=True))
df.head(20)
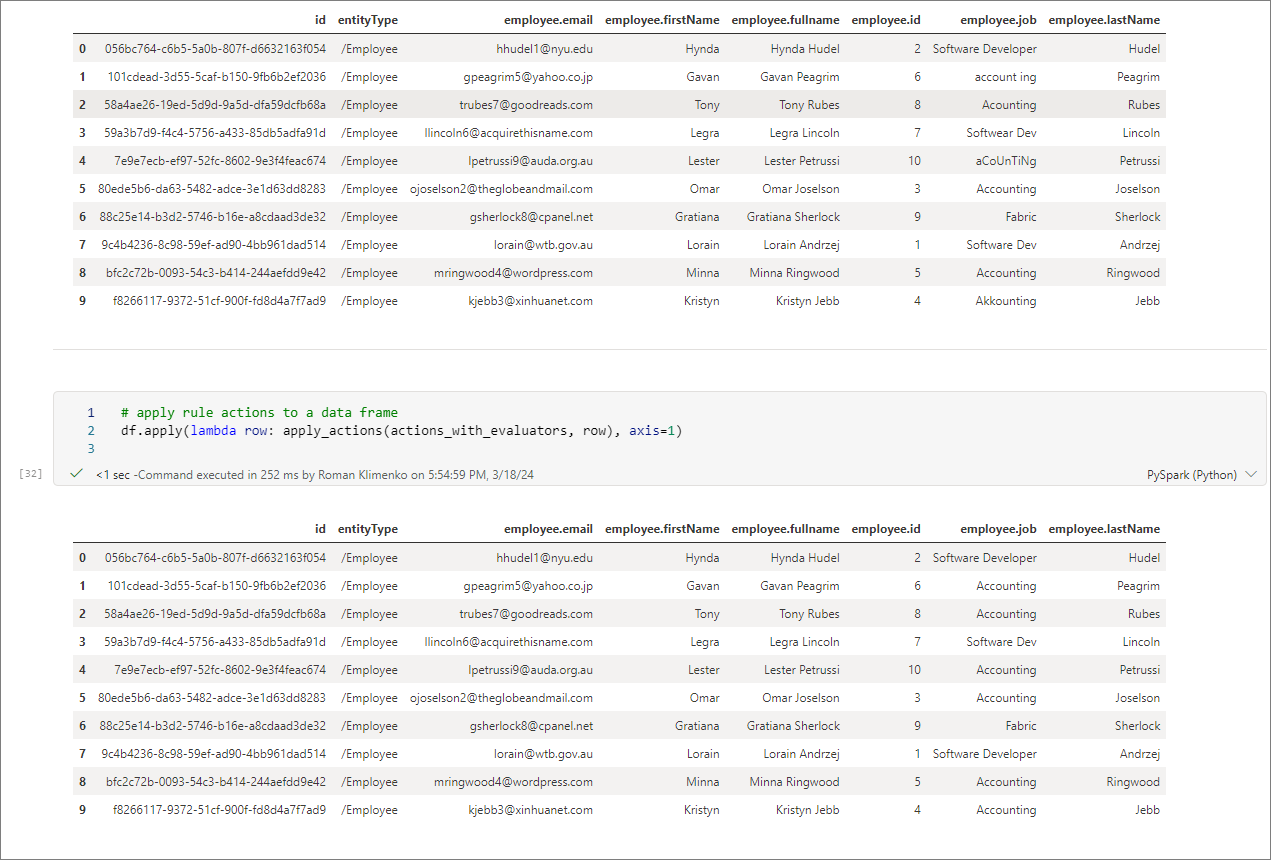
Apply rule actions to matching records:
# apply rule actions to a data frame
df.apply(lambda row: apply_actions(actions_with_evaluators, row), axis=1)
Filter data with evaluators
Filter the DataFrame with evaluators:
def evaluate(row):
return any(map(lambda evaluator: evaluator.object_matches_rules(row), evaluators))
df_filtered = df[df.apply(evaluate, axis=1)]
display(df_filtered)