Review mapping
On this page
After the mapping is created, review the mapping details to make sure that your records will be produced and merged in the most efficient way. This article will guide you through the essential aspects to check when reviewing your mapping details.
Before the data is processed, your mapping changes won’t affect the existing records in CluedIn.
To open the mapping details, on the Map tab of the data set, select Edit mapping. You’ll see three tabs containing all mapping details:
-
Map columns to vocabulary key – here you can check which properties will be sent to CluedIn after processing.
-
Map entity – here you can check the general details of the records that will be created after processing and the identifiers that will uniquely represent the records.
-
Add edge relations – here you can create rules for establishing the relationships between golden records.
Properties
On the Map columns to vocabulary key tab, check how the original fields will be mapped to the vocabulary keys in CluedIn after processing. The following actions are available for you:
-
Ignore certain fields if you don’t want to have them in CluedIn after the data is processed.
-
Map the original field to a different vocabulary key.
-
Add property rules to improve the quality of mapped records by normalizing and transforming property values.
Identifiers
On the Map entity tab, review the general mapping details and check the identifiers that will uniquely represent the records in CluedIn—primary identifier and identifiers.
What are general details?
-
Business domain and vocabulary.
-
Entity name – name of the records that is displayed on the search results page and on the record details page.
-
Preview image, description, date created, and date modified – record properties that you can find on the search results page and on the record details page. You can select which column should be used for each of these settings.
What is a primary identifier?
A primary identifier is a unique identifier of the record in CluedIn. If the primary identifiers are identical, the records will be merged. This merging is faster than creating a deduplication project because it is done on the fly and is based on strict equality matching. The deduplication project, on the other hand, is based on fuzzy matching and requires you to define matching criteria, making it a more time-consuming process. Even if you prefer to merge records by running a deduplication project, merging by primary identifiers produces cleaner, “pre-merged” records. As a result, the deduplication project will generate better results and be more performant.
Options for generating the primary identifier
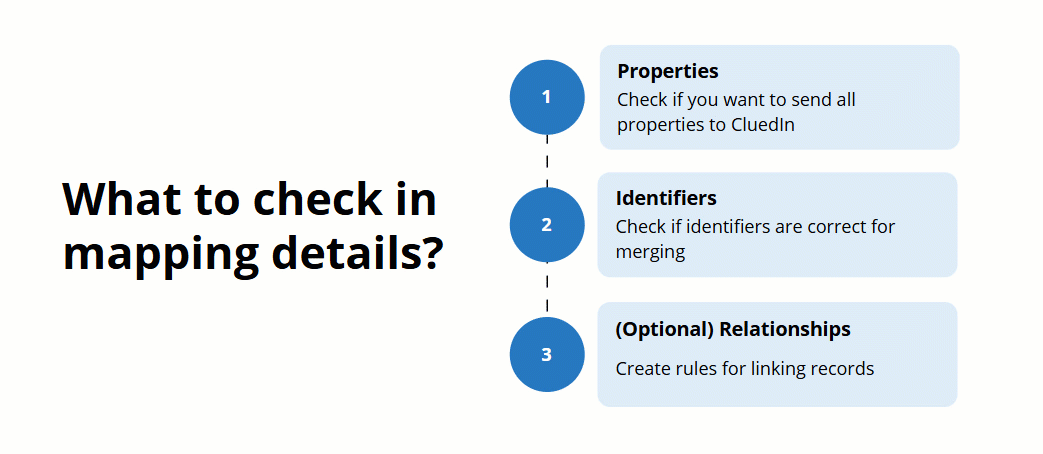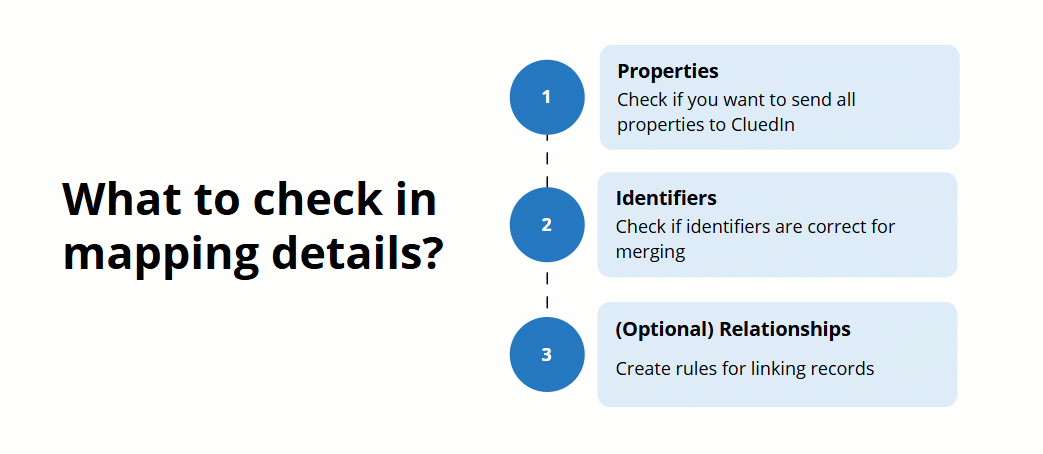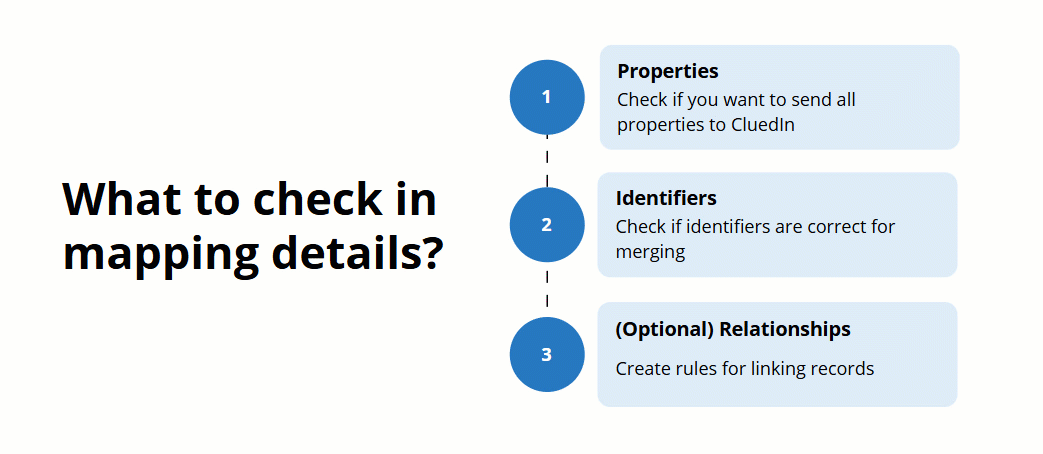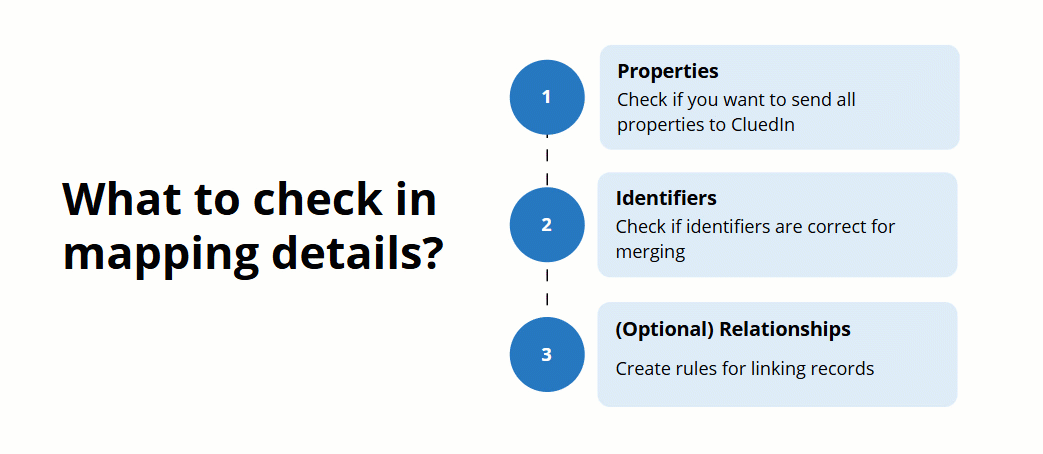
Depending on how unique you consider the records to be, you can choose one of the following options for generating the primary identifier:
-
Single key – CluedIn will generate unique primary identifiers for the records based on the selected property. This is the most commonly used option because data often already contains unique identifiers (for example, GUIDs) from the source systems.
-
Auto-generated key – CluedIn will generate unique primary identifiers for the records. Choosing this option may lead to an increased number of duplicates in the system, but you can mitigate this by running a deduplication project afterwards.
-
Compound key – CluedIn will generate unique primary identifiers for the records by combining selected properties. Choose this option if you are confident that the data structure won’t change in the future. For example, you can select the following properties to generate a compound key: First Name, Last Name, City, Address Line 1, and Country.
The following diagram will help you in determining which option to use for generating the primary identifier.
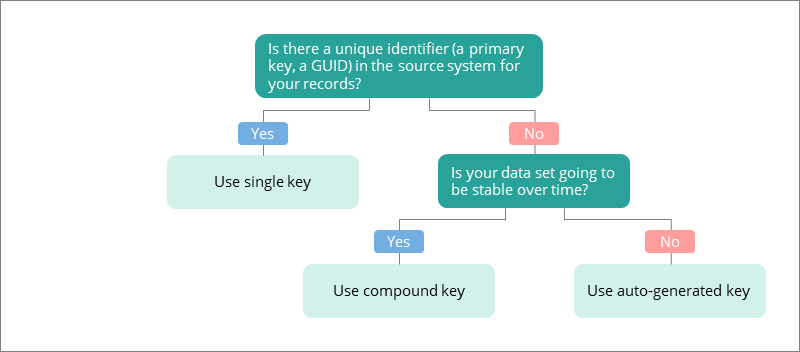
Example
We ingested a file with 1,000 records personal data containing the following columns: ID, First Name, Last Name, Email, SSN, and Country Code. To create the mapping, we selected the Auto Mapping type, and CluedIn automatically generated the mapping for the data set. Since our data set included the ‘ID’ column, it was automatically selected as the primary identifier. This is a favorable option because no empty or duplicate values were found during the current data set check. It means that the ID is a reliable value to uniquely represent the record in CluedIn.
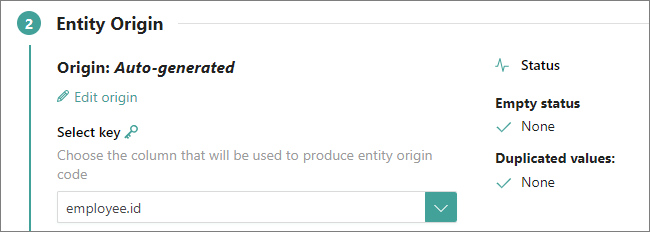
If we select a column that contains duplicate values (for example, country), the status check will immediately inform us of the number of duplicate values in the data set. By selecting View more details, you can view the number of duplicate values in the data set, which values are duplicates, and the number of times the duplicate value occurs in the data set. Referring to the screenshot below, there are 3 duplicate values in the data set: United States, Canada, and Spain. The value United States occurs in 550 records. If we proceed with this as the primary identifier and process the data, all 550 records will be merged into a single golden record. In this case, the country cannot serve as a unique representation for each record, as it is acceptable for records to share the same country.
However, if you are confident that the selected property can uniquely represent the record, you can proceed with processing the data. Records with identical primary identifiers will be automatically merged, eliminating the need for a separate deduplication project.
If the primary identifier contains an empty value, it is replaced with a hash. If your data set contains a record that is nearly identical to the one with the hash value, they will not be merged because the hash is a unique value. In such cases, you can initiate a deduplication project as a solution.
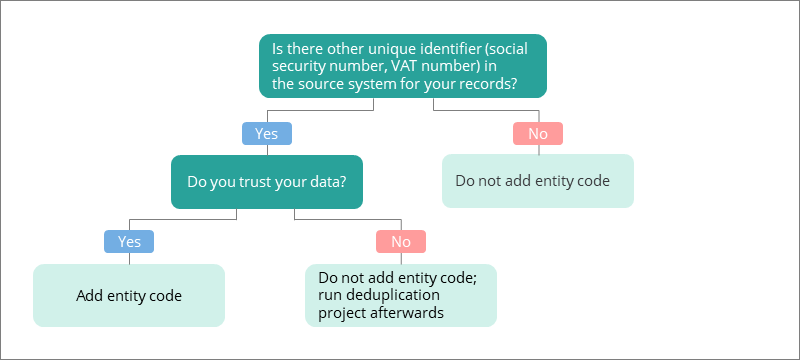
What are identifiers?
Identifiers can uniquely represent the record in CluedIn, in addition to the primary identifier. If two identifiers are identical, the records will be merged. CluedIn automatically detects properties that can be used as additional identifiers. For example, if the primary identifier is the ID, then the additional identifier could be the email.
Even if there are no duplicate values according to the primary identifier, but there are some according to additional identifiers, the records will be merged.
The following diagram will help you in determining if you need to add additional identifiers.
Relationships
A relationship is a connection or association between two or more golden records that indicates how the records are related or interact with each other.
If you want to connect the records from the current data set to other records in CluedIn, you can add relationships between such records. The procedure for adding relationships between records is described in our “Getting started” guide. For more information, see Add relationships between records.
You can add a relationship before or after you process the records. If you add a relationship after processing, you need to process the records again.
When you start creating a relationship, you have to select a property from the current data set that references another property existing in CluedIn. For instance, in the case of SQL tables, this property could be a foreign key that connects two tables. The relationship will be established based on the selected property. Then, you need to choose the edge mode:
-
Edge – CluedIn creates relationships between the records based on the origin.
-
Strict Edge – CluedIn creates relationships between the records that belong to a specific data set, data source, or data source group.
-
Fuzzy Edge – CluedIn creates relationships through fuzzy matching based on the Name property of the records.
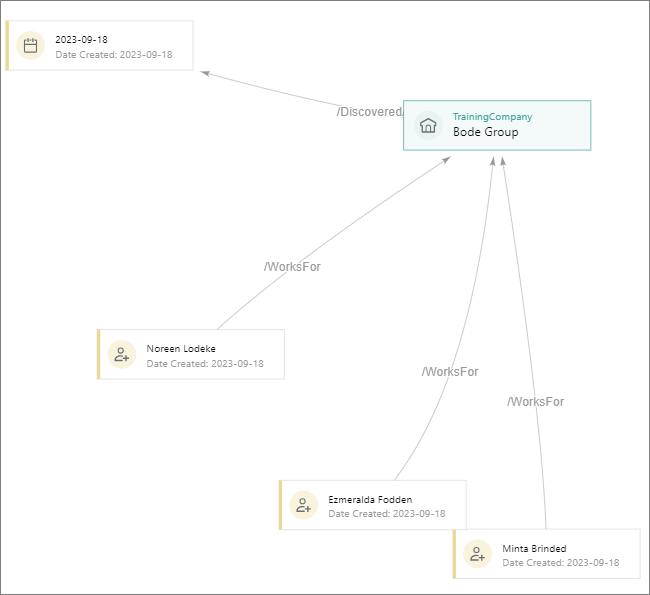
After you select the edge mode, you need to choose the edge type to define the nature of relationships between records (for example, /WorksFor, /RequestedBy,/LocatedIn).
Example
We have 2 data sets:
-
Companies – contains the following columns: Company_ID and Company_Name.
-
Employees – contains the following columns: EmployeeID, First_Name, Last_Name, and Company_ID. Here, the Company_ID defines the company where an employee works.
To connect employees to companies in CluedIn, we can create a relationship in the mapping details of the Employees data set. In this case, the Company_ID will serve as the property upon which the relationship is built. We select the Strict Edge mode because we are aware of the data set to which we want to connect the employees. Once the processing is complete, all employees who work for a particular company will be shown on the Relations tab of a company record.