Process data
On this page
| Audience | Time to read |
|---|---|
| Data Engineer, Data Analyst | 5 min |
You are here in the data journey
Before you start
-
Make sure you have conducted the data impact workshop to understand what sources you want to use first.
-
Make sure you are familiar with the available tools for data ingestion and have picked the right tool for your use case.
-
Make sure you have ingested the data, and the records are available on the Preview tab of the data set.
-
Make sure you have created the mapping for your records.
Once your records are mapped, you can now process them. Processing is the final step of the data ingestion process in CluedIn.

The act of processing means sending mapped records (clues) to the processing engine so it can either create new golden records or aggregate clues to the existing golden records.
Counting processed records
If the number of ingested records does not match the number of golden records, it means you had merges across the source. The merge can happen because of the same codes or because of deduplication projects being run. Generally, it is a good thing to have less golden records than ingested records as it means that CluedIn found duplicates.
What is a billable record?
A billable record is a new record that was processed from a data source. Learn more about billable records in a dedicated article.
What record is considered a new record?
A new record is a unique record that comes from a source of data and is processed in CluedIn. If you repeatedly send the exact same record within the same source, it won’t be added to your billable records count. Each time CluedIn processes records, it keeps a hash code that represents the record. As some source systems do not support deltas, we do not want you to have your billable records increased due to this shortcoming. So, if the record within a source has the exact same hash code (same collection of attribute/value), it won’t be added to the billable records count.
Keep in mind that changing the mapping can change the hash code of records, leading to those records being counted as new billable records. However, if you remove records from CluedIn, the number of billable records will decrease. So, if you require a major change in your mapping, make sure you remove the records you want to change to avoid having an increase in billable records.
Pre-processing options
There are a number of actions you can do to change the records right before they are sent to the processing engine. These actions can be grouped into 2 categories: avoiding unwanted records and modifying the records before processing.
Avoid unwanted records
If you do not want to send specific records from the data set to the processing pipeline, you can set up rules to send such records to quarantine. Learn more about quarantine in a dedicated article.
Modify records before processing
-
Advanced mapping – you can write a glue code in your data set to modify the records before they are processed. This is useful for complex and conditional mapping. Learn more about advanced mapping code here.
-
Property rules – improve the quality of records by normalizing, transforming, or changing property values before the records are processed. Learn more about property rules here.
-
Pre-process rules – execute some basic operations on the records before they are processed. Learn more about pre-process rules here.
Generally, you should use the above-mentioned options to normalize or denormalize values in the records before they become golden records. Even though CluedIn is a tool to fix data quality issues, it can be useful to do some preparation before processing. This ensures that the advanced mapping code and rules remain close to the source and run only on the source records. If the records were already processed, the same activity would run on a large set of golden records. Therefore, if an issue appears only in a specific source, then it is a good idea to fix it with pre-processing rules, as the manipulation would be specific to that source. However, if the fix could benefit multiple sources, then do not add pre-processing rules, and add a classic rule instead.
Types of processing
In CluedIn, there are two types of processing—manual and automated. Choosing the suitable type depends on how you ingest a source of data and how often you need to process records.
| Source details | Suitable processing type |
|---|---|
| Source is ingested one time only | Manual |
| Source is a sample data | Manual |
| Source is ingested once a month | Manual |
| Source is ingested for the first time | Manual |
| Incremental batch of records | Automated* |
| ADF pipeline | Automated* |
* Switch to automated processing after you verify that the mapping and pre-processing actions work fine on a data sample.
It is always a good idea to start with manual processing, especially at the initial stages of data ingestion. Since mapping has a significant influence on golden records, we recommend that you start with small data set and manual processing. This way you can verify that the golden records are accurate and then switch to automated processing.
Keep in mind that CluedIn will skip the exact same records during processing—on the condition that mapping remains unchanged—so you can process the same data set multiple times.
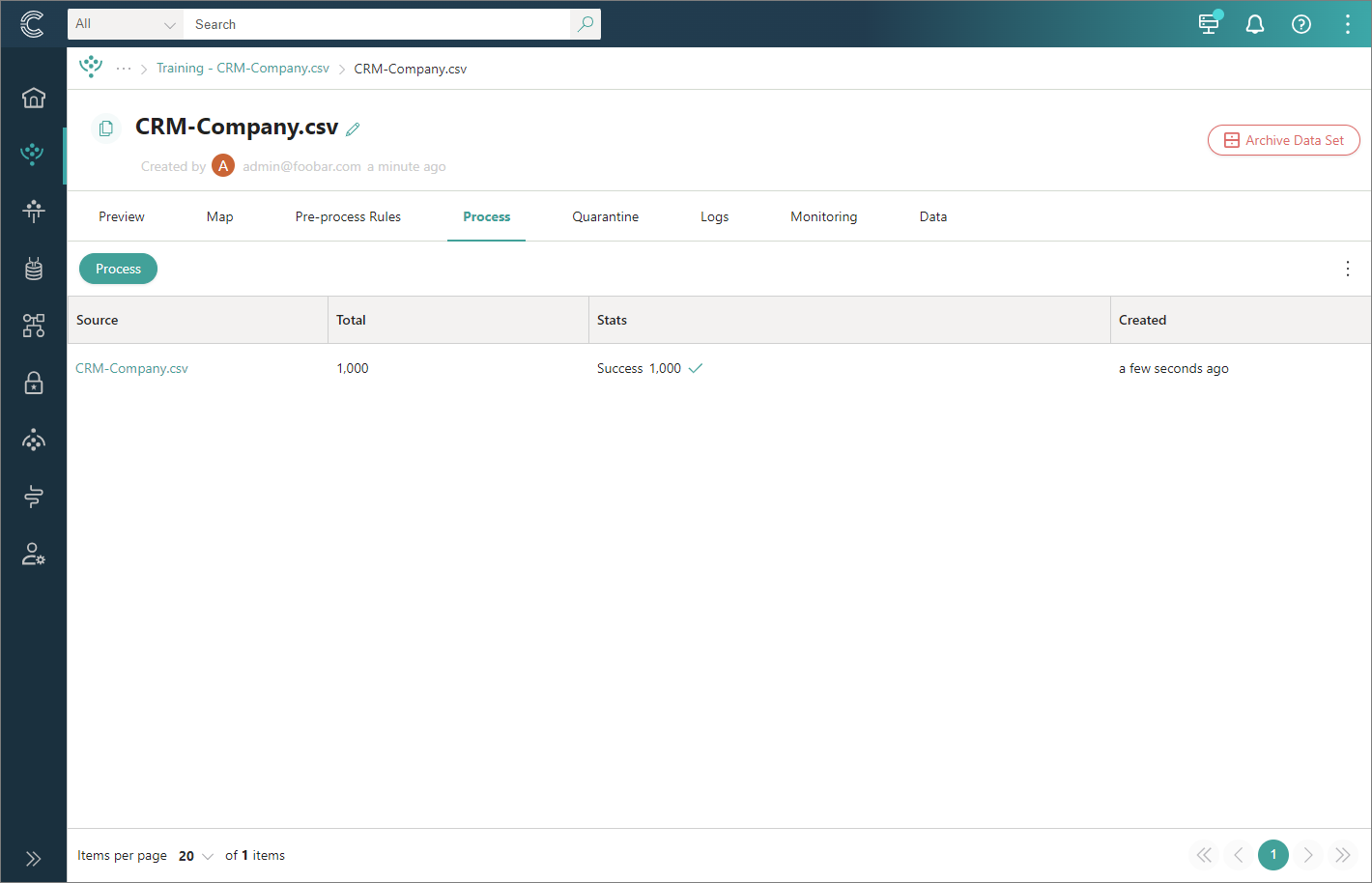
You can find step-by-step instruction for processing records in a dedicated article. Once the processing is done, you will see the result similar to the following.
Next steps
Now that your records have turned to golden records, you can start searching for them using the main search.
Processing concludes the data ingestion step of your data journey. Next, you can start the data transformation activities.