Concept of mapping
On this page
- Core mapping terms
- Mapping process overview
- Setting up the right identifiers
- Main decisions in mapping
- Next step
| Audience | Time to read |
|---|---|
| Data Engineer, Data Analyst | 5 min |
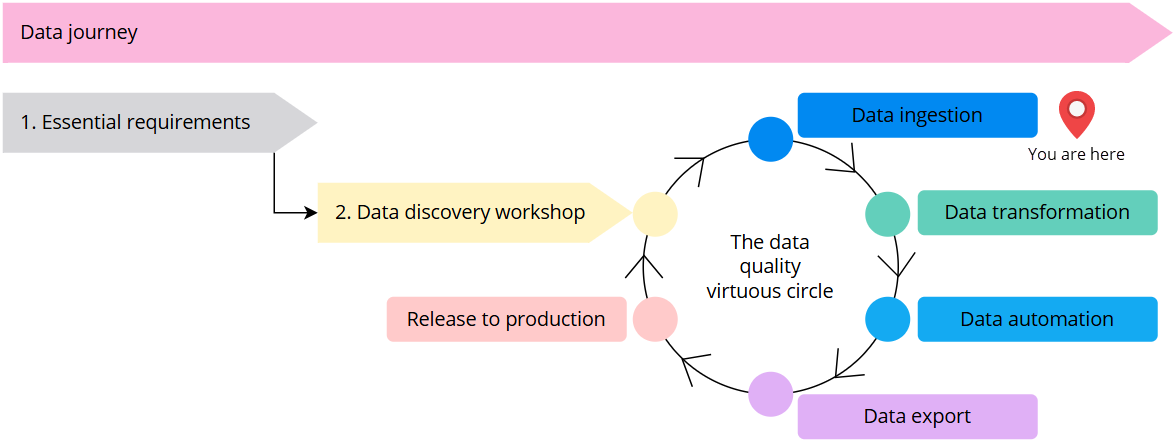
You are here in the data journey
Before you start
-
Make sure you have conducted the data impact workshop to understand what sources you want to use first.
-
Make sure you are familiar with the available tools for data ingestion and have picked the right tool for your use case.
-
Make sure you have ingested the data, and the records are available on the Preview tab of the data set.
Now that you have ingested the data using the tool of your choice, the next step is to create mapping. However, before doing so, we recommend that you get acquainted with the overall concept of mapping. After all, starting the mapping process without understanding the core concepts can lead to issues later. Mapping is one of the most important steps in CluedIn, and we know it can be tricky initially. We understand that the learning curve is a bit steep, but hopefully with these playbooks you will be able to navigate it successfully.

Core mapping terms
The goal of mapping is to add a semantic layer to your records that allows CluedIn to better understand your records. This is a requirement for processing your records into golden records.
The mapping uses multiple CluedIn terms that you will need to learn. While it may not be absolutely critical at the start of the project, we believe that a minimal level of understanding is necessary. The following table lists the most important mapping terms, their purposes, and links to relevant documentation.
| Name | Purpose | Link to documentation |
|---|---|---|
| Business domain | The business domain represents a specific business object that describes the semantic meaning of your data. Read the documentation to understand how to choose a good business domain. | Link |
| Vocabulary and vocabulary keys | The vocabulary is used to define the semantic layer (metadata) for your data. The vocabulary contains vocabulary keys that describe the properties coming in from the data source. Read the documentation to learn about vocabulary usage. | Link |
| Identifiers | This is a mechanism that CluedIn uses to define the uniqueness of a golden record. Read the documentation to understand the concept of primary identifier and identifiers. | Link |
| Origin | The origin generally determines the source of golden records, and it is used in identifiers. Read the documentation to understand the importance of the origin. | Link |
Mapping process overview
When you create mapping, you are essentially transforming your initial raw records into a format that CluedIn can understand. We call this format a clue. In terms of medallion architecture, a clue is a silver record.
To get a good default mapping configuration, use the auto-mapping option.
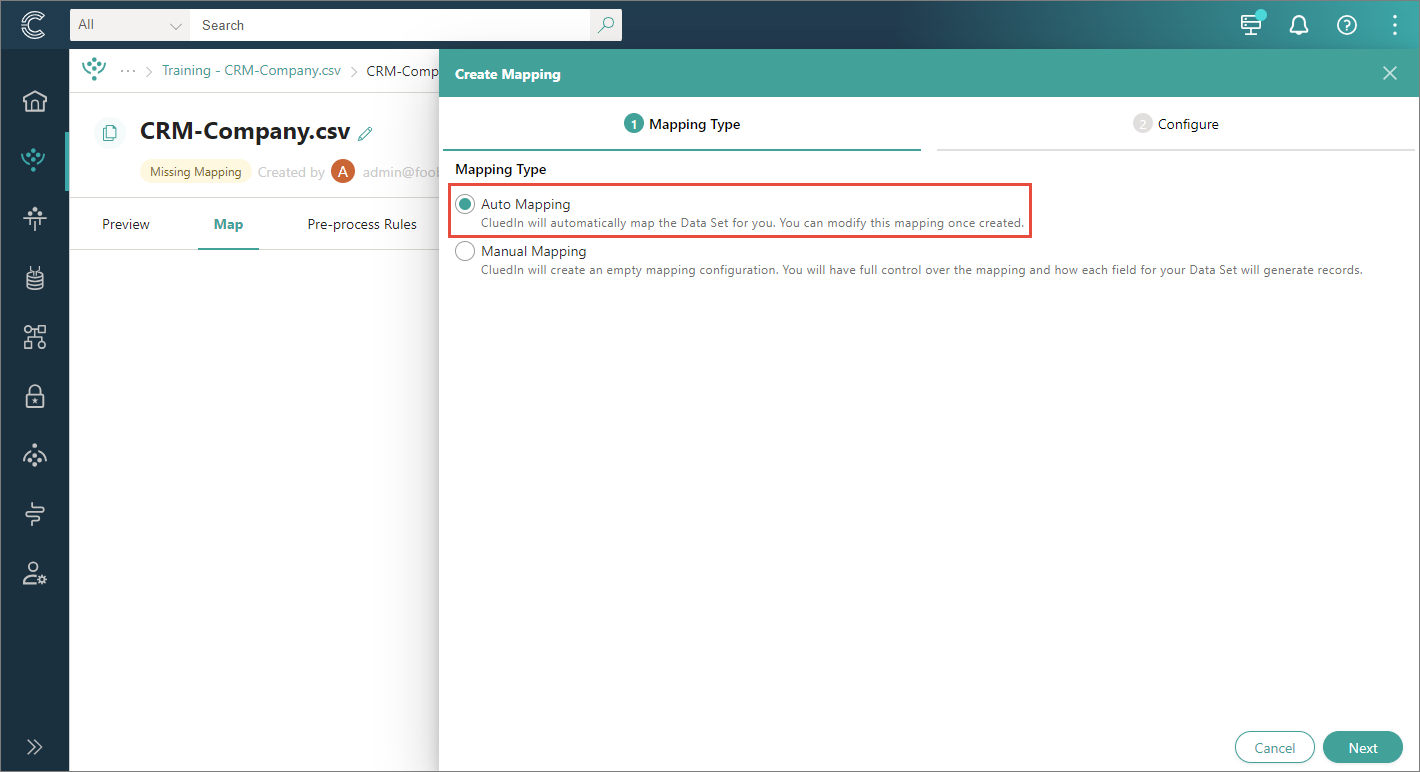
It is a great way to start and define the most important mapping attributes—business domain and vocabulary. You can learn more about the process of creating mapping and find step-by-step instructions in a dedicated article.
For lineage purposes, we recommend keeping a vocabulary close to the source. Later, you can map the vocabulary keys to generic, shared vocabulary keys. When you have multiple sources with vocabulary keys mapped directly to the generic, shared vocabulary keys, it can become overwhelming to have more than 10 sources mapping directly to your golden records. In order to avoid confusion for those consuming the records, it is a good practice to map to the source vocabulary first.
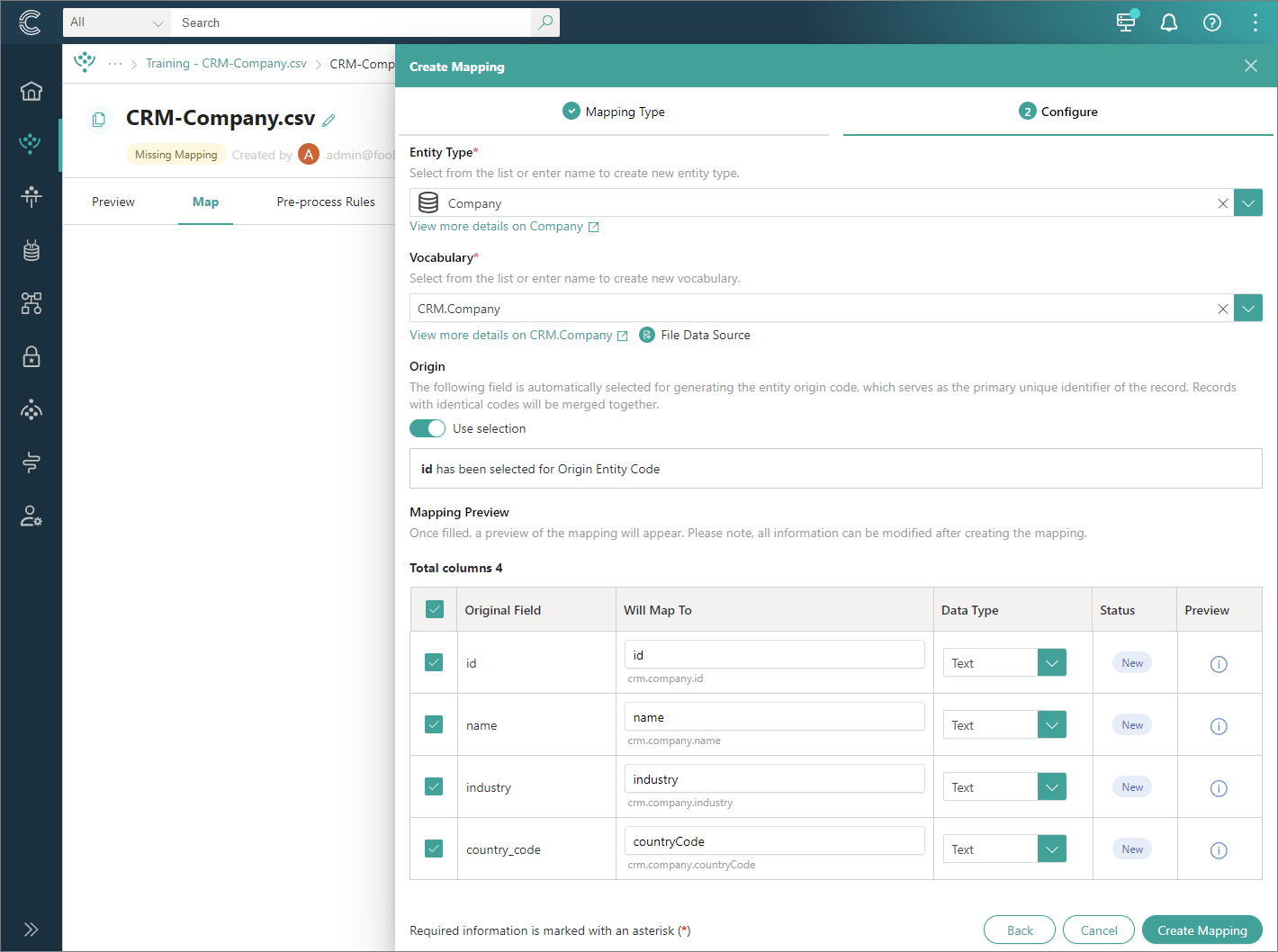
Setting up the right identifiers
After you selected the right business domain and vocabulary, it’s time to choose the right key to produce the identifiers for your records.
Poorly defined identifiers can have a truly unexpected impact. The most common pitfall of poorly defined identifiers is what we call over-merging. It happens when you set up an identifier that is not actually unique. Suppose you choose the country code as a key, then all records with the same country code will merge together into one record. For example, if you have 100,000 records with the country code of “DK”, then all those 100,000 records will end up as 1 record.
Poorly defined identifiers can cause system slowdowns. While reverting is possible, it will take time as now CluedIn will need to split those records. At that point, the fastest solution is to remove those records from CluedIn and restart the mapping. With the country code example, it is easy to understand that using non-unique properties as identifiers is not a good choice.
Sometimes, the key you consider unique is not in fact unique. For example, a SKU code—unique internal product code—can have the following issues:
-
-as a value. -
NULLas a text value. -
N/A,N-A, or any other combinations. -
Records sharing the same code, even if it is supposed to be unique.
-
Wrong value (for example, email in place of the actual value).
Of course, CluedIn has ways to fix such data quality issues. However, if you blindly choose a key to produce an identifier, it may lead to issues. To avoid this, CluedIn tells you the potential duplicates you have in your records before processing.
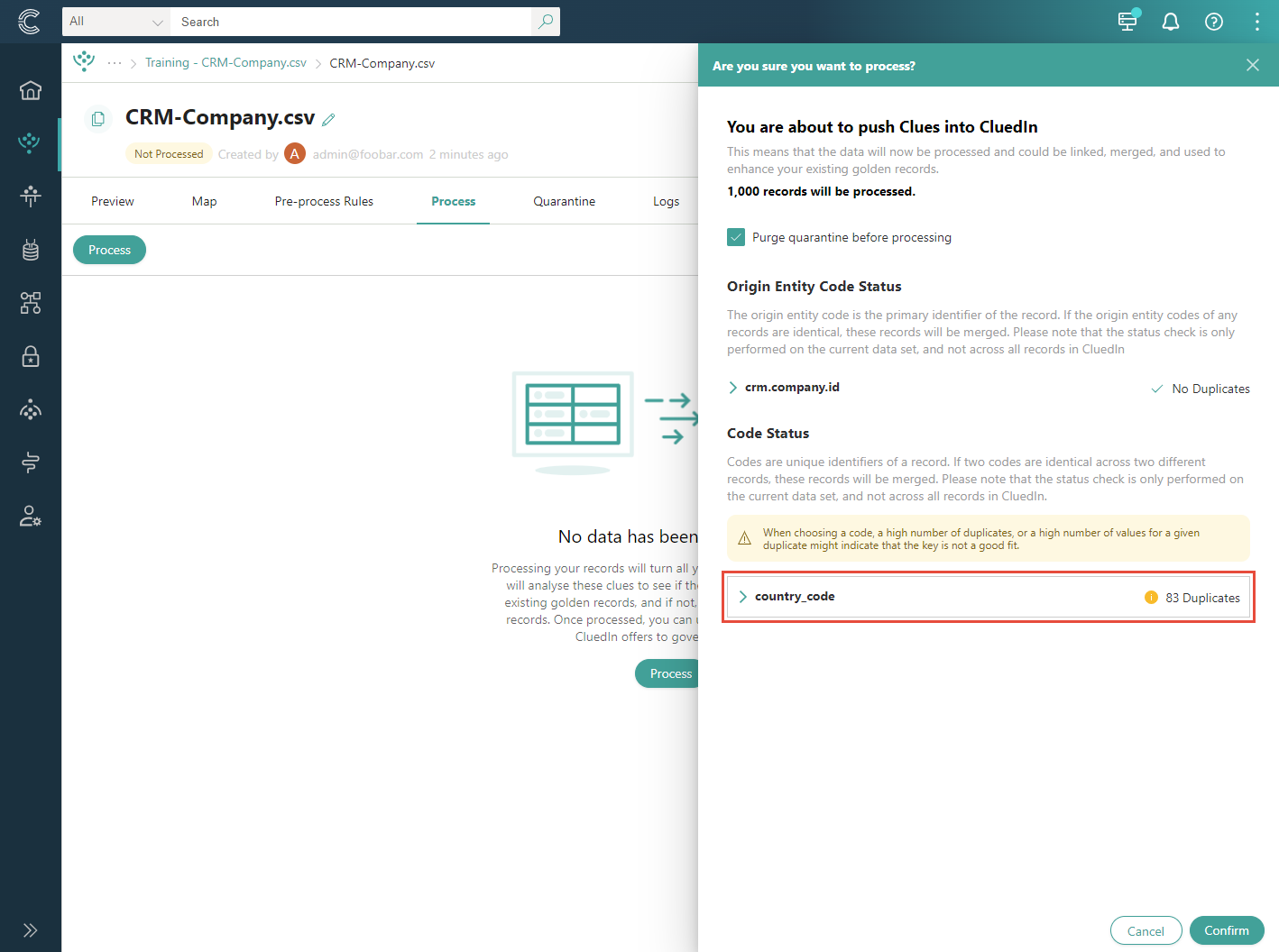
Main decisions in mapping
This is an introductory article on the topic of mapping. We’ll add more detailed articles soon, as mapping is a significant part of the processes in CluedIn. As an outcome of this article, you know about 2 important decisions you have to make while creating mapping:
-
Choose the right business domain.
-
Choose the right vocabulary that is close to the source.
Additionally, you now know about the importance of choosing the unique key for producing the identifiers. If you are unsure whether the selected key is unique, you can use a deduplication project to detect and merge duplicates.
Next step
After creating the mapping, you can process your records to produce golden records.