Pick the right tool
On this page
- File
- Endpoint
- Azure Data Factory
- Microsoft Fabric
- Microsoft Purview
- Database
- Crawler
- Tools reference
- Next step
| Audience | Time to read |
|---|---|
| Data Engineer, Data Analyst | 7 min |
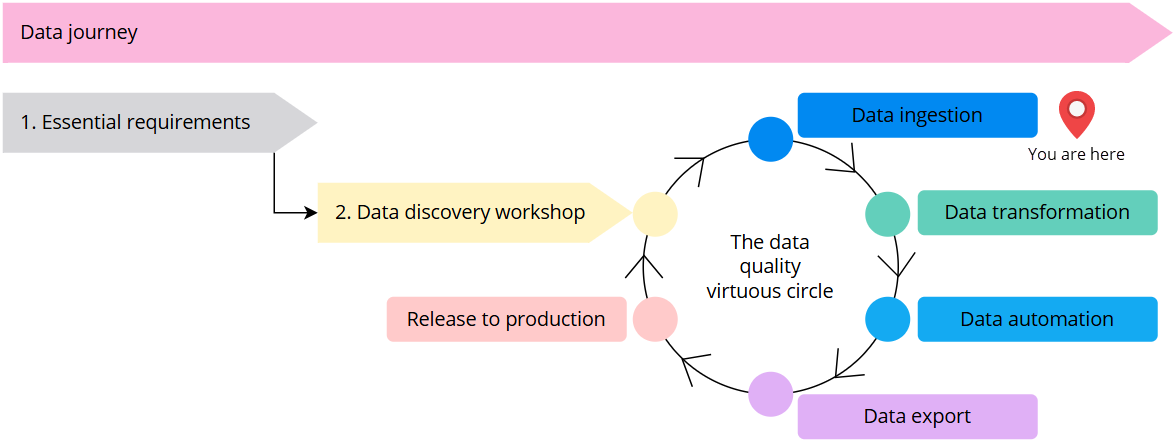
You are here in the data journey
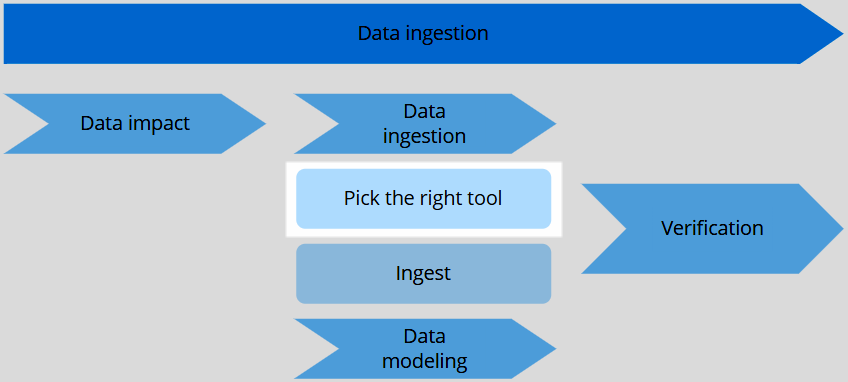
Before you start
- Make sure you have conducted the data impact workshop to understand what sources you want to use first.
This article outlines all the possible tools that can be used to ingest data into CluedIn. By understanding the specifics of each tool, you can decide which one will be the most suitable for your use case.
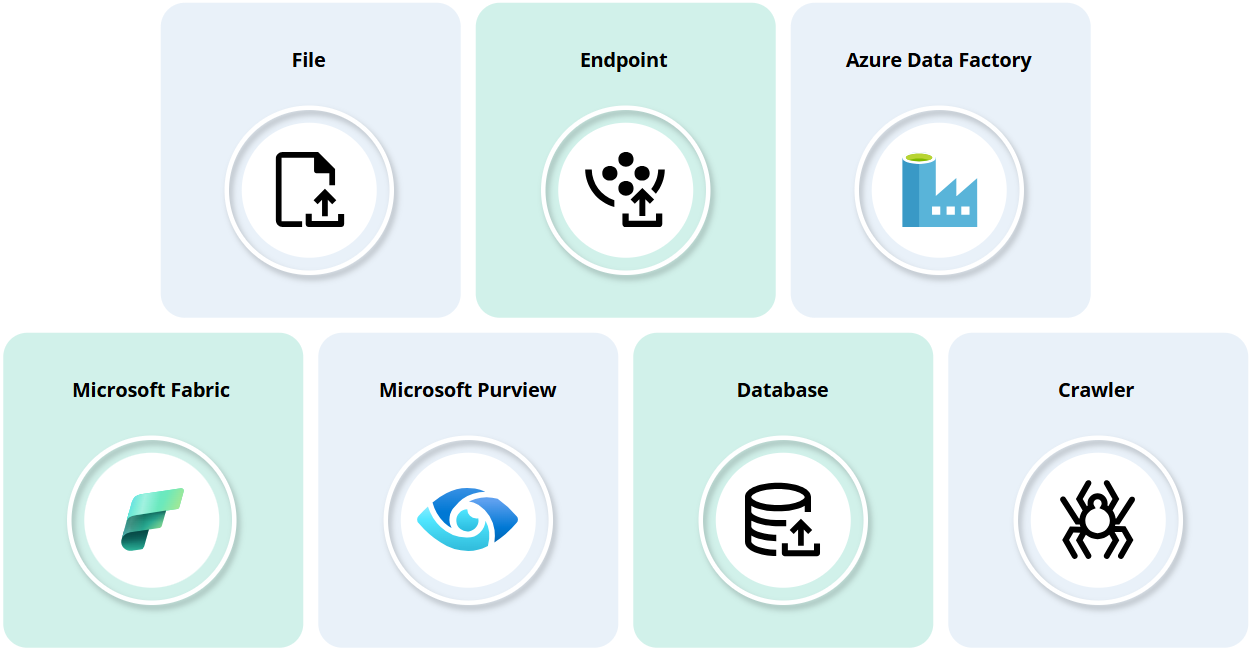
Now that you have a list of sources that you want to use, you can prepare a data ingestion plan. The first decision to make is how to ingest the data. CluedIn provides multiple out-of-the-box options for data ingestion (as shown in the diagram below). However, the best way to get the data from the source depends on your infrastructure.
File
CluedIn supports the following file formats to upload your records into the system: CSV, JSON, XLS, XLSX, and Parquet.
When to use files for data ingestion?
-
When you need to provide a data sample.
-
When the source system will be decommissioned.
-
When you need to manually export the data from the source system due to various reasons (for example, an internal policy, a limitation of the source system, a choice from the business not to have live connection with the source).
The files are quick and easy to ingest. However, opting for files removes the automated pipeline aspect of your MDM project, resulting in more manual operations for a source. It is up to you to decide if having some of your records manually uploaded is sufficient for you. All in all, file upload should be primarily used for testing purposes and data sampling to set up your mapping or test some rules, ideally in a sandbox environment.
Endpoint
The endpoint is the most generic way to send data to CluedIn. It is a simple HTTP POST endpoint to send JSON array to CluedIn. This lightweight method allows you to operate with any kind of system, provided you have the ability to make an HTTP request.
The endpoint is used as the underlying mechanism for integration with Azure Data Factory, Microsoft Fabric, and Microsoft Purview.
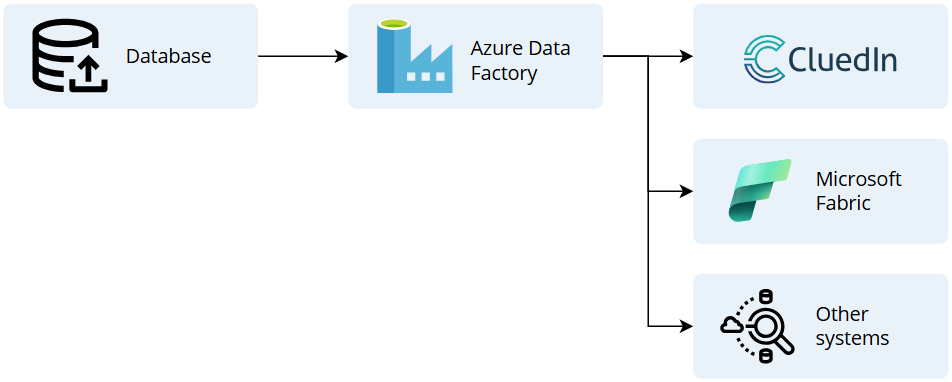
Azure Data Factory
Azure Data Factory is a great tool for creating data pipelines and pushing data into CluedIn. With hundreds of connectors available, it’s highly likely that you’re already using Azure Data Factory. This makes it the recommended option for data ingestion.
Why is Azure Data Factory a recommended data ingestion option?
-
It makes the data pipeline more extensible—you can load the data once and add extra pipeline steps to send data to other systems in addition to CluedIn.
-
The data flow is less dependent on the MDM system, meaning you can reuse the data pipeline to send data to other systems.
-
Azure Data Factory is simple to set up and run, and connecting it to CluedIn is easy. Once you’ve configured it for one source, you can easily do the same for all other sources.
Microsoft Fabric
If your sources are not supported by Azure Data Factory, check if they are supported by Microsoft Fabric, which also offers many connectors that allow you to connect to different types of data stores.
Data engineers may prefer Microsoft Fabric, as they often favor writing Python code over setting up data pipelines through a UI. However, we believe this decision should be made as a team, as it implies that an engineer will be required to upgrade and maintain the data pipeline. We are not aware of the skills and dependencies of each data team, so it will be up to you to decide. In any case, CluedIn can easily connect to Microsoft Fabric as described here.
Microsoft Purview
If you are a Microsoft Purview user and you want to sync your assets with CluedIn, you can do so using our Purview integration as described here.
To configure Purview integration, you need to take into account how the assets are connected. Specifically, it matters whether you need to integrate the assets from an existing data pipeline or architecture, or if you can directly connect the assets with your MDM project. If the latter is your option, then Purview integration will fit your needs. It will help not only govern your assets but also to fix the low-level data (records) from those assets, improving data quality.
Database
CluedIn can connect to various types of databases, supporting MS SQL, MySQL, and Postgres dialects. This option allows for full or partial data ingestion; however, we recommend using it as a one-time operation.
When to use databases for data ingestion?
-
When you want to import data from an old MDM project.
-
When you want to decommission old systems and keep your MDM project as a sink for data.
-
When you have small to medium-sized databases (1 million records per table) that do not have many changes over time.
-
When your databases are not connected to other systems. This way you can avoid putting pressure on your databases.
What to do if you have large databases?
If you have large databases that need to connect to multiple systems, we recommend using an Azure Data Factory (ADF) pipeline. This approach ensures that the ingestion process within your data ecosystem is done only once, reducing the load on your database. Additionally, it provides greater extensibility if you need to add extra pipeline steps to send data to other systems.
Crawler
When all of the above options do not fit your needs, you can use a crawler mechanism that we built to get data into CluedIn. One of the possible uses of a crawler is to migrate from Master Data Services (MDS) to CluedIn.
Over the years, we have built many crawlers, some of which are very specific and tailored for customers. While this is not our first choice, be aware that this option exists and can be used when you really need custom solution. Of course, charges may apply if CluedIn needs to write custom code solely for your use case.
If your data engineers know C#, they can also build their own crawler with CluedIn if they want to. The template is open source and can be used if required. However, please reach out to us before pursuing this option, as it would need to address a very specific and tailored use case that none of the aforementioned tools can handle.
Tools reference
This section provides brief descriptions of the usage for each data ingestion option.
| Data ingestion type | Usage |
|---|---|
| File | Use files for data ingestion as a one-time operation in scenarios such as decommissioning a system, providing a data sample, or when the source owner is reluctant to give direct access to the source. |
| Endpoint | This option represents a generic way to push data into CluedIn by sending an HTTP request with a JSON array. |
| Azure Data Factory | With many connectors maintained by Microsoft, this option is a good choice to create data pipelines and send the data to CluedIn. An ADF pipeline can be set up by a person with no coding experience. |
| Microsoft Fabric/Azure Databricks | This option is suitable for you if you already use Microsoft Fabric (or Azure Databricks). It offers many connectors, but may require writing Python code to set up the data pipeline. |
| Microsoft Purview | Connect to Microsoft Purview if you want to sync and clean some assets from Purview using CluedIn. |
| Database | Use database ingestion as a one-time operation in scenarios such as decommissioning a system or when dealing with small to medium-sized databases that are not connected to other systems. |
| Crawler | Use crawlers for Master Data Services (MDS) migrations or in scenarios where a connection to Azure Data Factory or Microsoft Fabric is not feasible. If needed, you can write a custom crawler for source ingestion using C#. |
Next step
After defining the tools you’ll use for ingesting your sources, you can start the actual ingestion process as described in Ingest data.