How to approach your CluedIn project
On this page
| Audience | Time to read |
|---|---|
| Business User, Data Project Lead, Data Steward, Data Analyst, Data Architect, Data Engineer | 5 min |
This article outlines two fundamental steps for approaching any data project in CluedIn. Following these steps will help you achieve attainable value right from the start.

Start small
Regardless of your use case, we always recommend starting your data project in CluedIn with a limited number of records from one or several data sources. By experiencing full CluedIn cycle—ingest, clean, deduplicate, and stream—on a small scale first, you can thoroughly understand the process before scaling up in terms of records and sources.
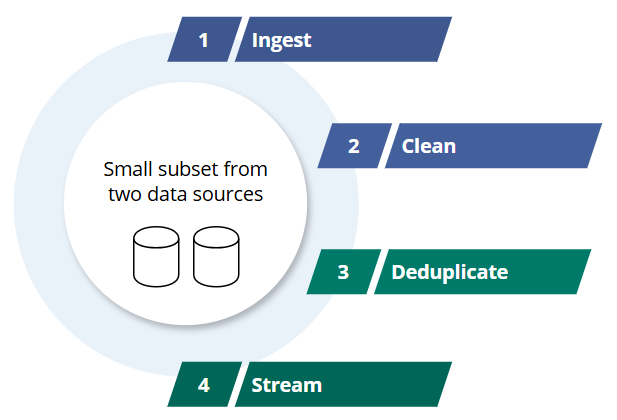
Here are the key benefits of starting small:
-
Agility and flexibility – quickly adapt and iterate based on immediate feedback.
-
Fast learning – understand the CluedIn process on a manageable scale.
-
Quick adjustments – make necessary changes without the overhead of managing vast amounts of data.
-
Reduced risk – minimize the risk of large-scale failures by perfecting the process on a smaller data set.
One of our guiding principles is: “Aim for better data, not perfect data”. Striving for 100% perfection from the start often leads to failure, which is why we advocate for an Agile approach. This allows for continuous improvement and adaptation.
While CluedIn simplifies MDM processes, handling a vast amount of data from the start can be overwhelming. This is why starting small allows you to tackle these MDM challenges:
-
Complexity in MDM steps – each MDM step can introduce significant complexity. Managing 100 records is far easier than managing 1,000,000 records.
-
Load on source systems – even though CluedIn can handle it efficiently, ingesting millions of records can impose a considerable load on source systems, slowing down your progress and increasing the risk of errors.
-
IT obstacles – each data introduces a unique set of IT challenges. You might need to contact multiple data owners, navigate permissions, and deal with network security issues.
What happens if you don’t start small?
Approaching a data project with the traditional Waterfall methodology can be rigid and slow. Initially, you would ingest data from all your data sources. Next, you would clean the data. Only after that would you perform deduplication activities. At any stage, there’s a significant risk of errors due to the large volume of data.
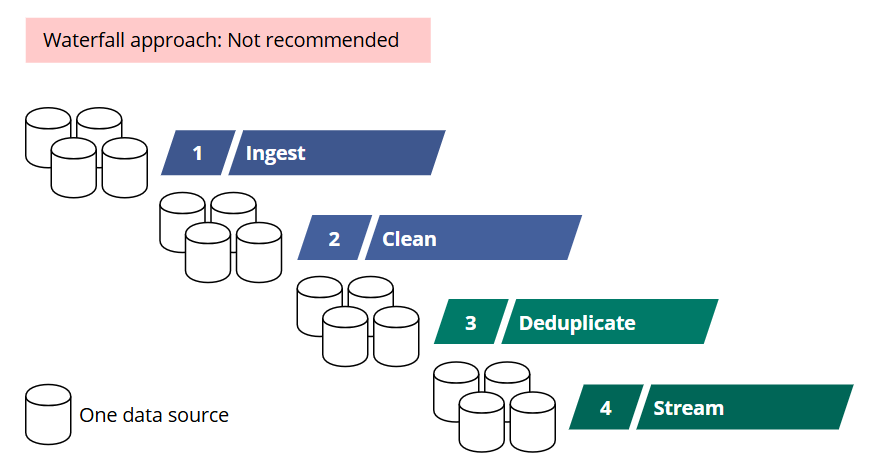
Let’s say you have 10 sources, each with 1,000,000 records, and you ingest data from all of them before any cleaning or deduplication activities. This whole process could take months, annoy your IT team, and you would not have improved the quality of your data at all.
Suppose you succeeded to ingest those 10,000,000 records. Next, you will have to apply cleaning and deduplication rules on a whole difference scale. Of course, CluedIn allows you to filter down and clean and deduplicate your records on a smaller scale. However, keep in mind that cleaning 1,000 records out of a set of 10,000,000 means that these records can be merged or exported to other parts of the system, such as rules or streams. This means you won’t have control over your data and will be forced to play catch-up to determine what should have been done earlier. Additionally, you’ll need to stream large amounts of data multiple times whenever changes are made.
Although CluedIn’s streams are performant, it is always easier to stream 1,000 records, then 10,0000, and finally 10,000,000, rather than streaming 10,000,000 records three times.
Embrace Agile
In CluedIn, we believe it is essential to create value as soon as possible. Start by improving small data sets from various sources, and then expand along two dimensions: the number of records and the number of sources. Start with the data you have; don’t wait—improved data is better than your current data. Therefore, focus on creating a virtuous cycle before adding more data.
You can start with as little as 10 records and achieve the value immediately. With those 10 records, you can learn how to perform the main tasks in CluedIn:
- Map
- Enrich
- Clean
- Apply business rules
- Deduplicate
- Stream
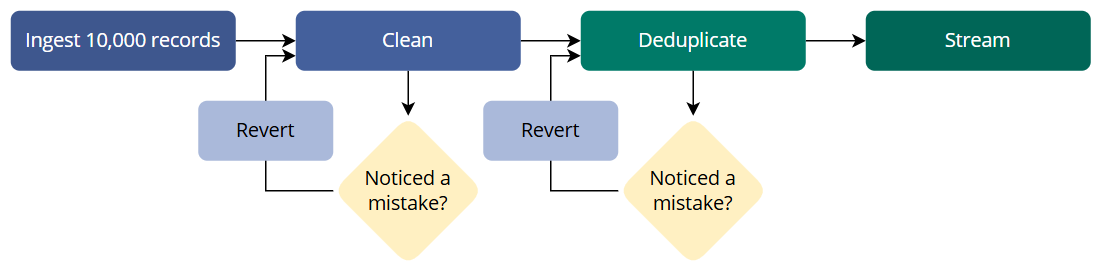
Once you have successfully ingested, cleaned, deduplicated, and streamed a small dataset of 10 records, you can scale up and apply the same process to a larger set of 10,000 records. The more exercises you do, the deeper your understanding of data will become. If you make a mistake at any step, you can always revert your work and try again until you achieve the desired outcome. This iterative process ensures that you add value to your data and enhance your knowledge of CluedIn.
Our experience with data projects has shown that initial perceptions of data quality often differ from reality. This is a common and manageable challenge, and we are here to help you enhance your data quality and reveal its potential.