Processing logic in clean projects
On this page
- Processing clean project changes
- Pre-processing: comparing values
- Processing: applying survivorship rules
In this article, you will learn about the underlying mechanisms involved in processing clues generated by the clean project. The following diagram illustrates the processing logic for clues generated from the clean project.
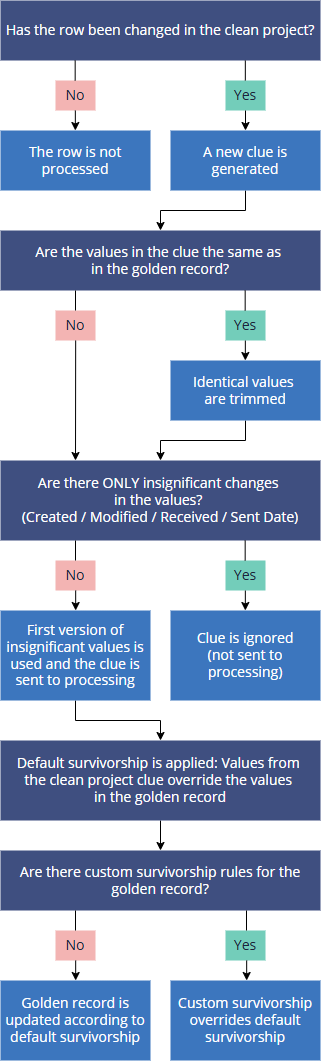
Processing clean project changes
When you generate a clean project, all data is copied to the clean application. While working in the clean project, the golden records in CluedIn may be modified by other processes. Therefore, when submitting your clean project changes, you must decide how to handle golden records that have been changed outside the clean project:
-
Push – apply all cleaning changes, even if golden records have been modified outside the clean project. This action forces the application of all changes without checking for outdated data.
-
Skip – do not apply cleaning changes to golden records that have been modified outside the clean project. This action checks for outdated data and ignores changes for stale records.
If you choose to push all cleaning changes, then CluedIn will first verify whether any modifications were made within the clean project.
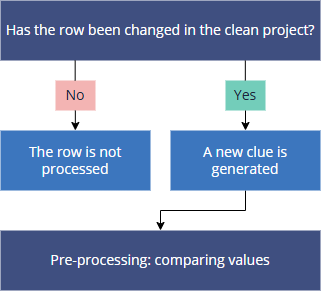
Each row is evaluated based on whether it was modified in the clean project:
-
If a row has not been changed in the clean project, it will be skipped during processing.
-
If a row has been changed in the clean project, then a new clue will be generated with the data from the clean application. Then such clue will be sent to the pre-processing step.
After checking for changes in the clean project, CluedIn compares values in the clean project clue and the golden record.
Pre-processing: comparing values
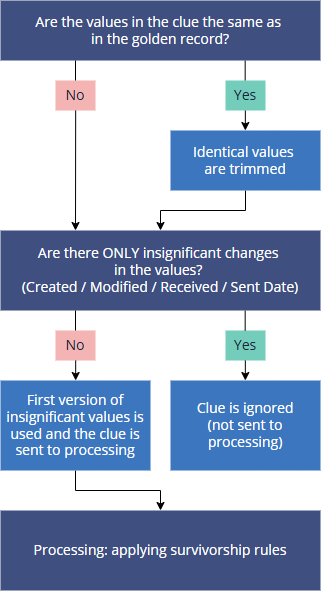
During the pre-processing step, CluedIn checks the golden record that the clue is going to be merged into and compares golden record values with those in the clue:
-
If the values are identical, CluedIn trims these values from the clue and passes it through the regular processing pipeline. Essentially, CluedIn checks the persist hash of each row—if a hash already exists in the golden record, the clue is not merged.
-
If the values are different, the clue is added to the history of the golden record. At this point, CluedIn compares the clue with the previous revision in the same version branch. It is important to note that the comparison takes place with the previous revision in the same version branch and not with another version in the golden record history.
If CluedIn finds insignificant changes—Created Date, Modified Date, Received Date, Sent Date—they are skipped. Generally, the first version of such properties is used in the golden record. Note that you can configure the vocabulary keys that are considered insignificant. This can be useful when you have frequent changes sent from the source system or when the source system generates hashes. If a clue consists only of insignificant changes, then such clue will not be added to the golden record. If a clue consists of both significant and insignificant changes, then such clue will be added to the golden record.
After the pre-processing step, CluedIn applies survivorship rules.
Processing: applying survivorship rules
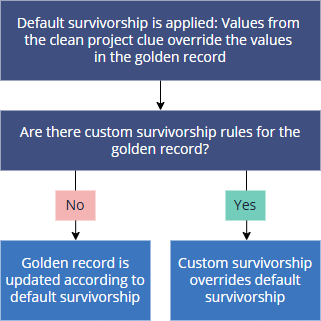
Changes from the clean project are treated as manually added. This means that the default survivorship mechanism is applied to the clean project clues—manually added changes always win over changes from other sources. If you have multiple manually added changes, the most recent one wins. Learn more about default survivorship rule here.
During processing, CluedIn initially applies the default survivorship mechanism, followed by custom survivorship rules. Therefore, if you want to override default survivorship and always use values from the source system, you can create a custom survivorship rule.