Deduplication reference
On this page
- Matching rules
- Matching functions
- Normalization rules
- To lowercase
- Trim whitespace
- Remove punctuation
- Remove special characters
- Remove diacritic marks
- Person name variations
- First name nickname variants
- Organization name
- Organization name postfix
- Phone number
- Email mask
- Street address normalization
- Geography country
- Replace text
- Regex replace text
- Split text
- Regex split text
- Split text by whitespace
- Transliterate
- Deduplication project
- Group of duplicates
- Deduplication project audit log actions
In this article, you will find reference information to help you understand matching rules and functions, normalization rules, deduplication project statuses, and group statuses.
Matching rules
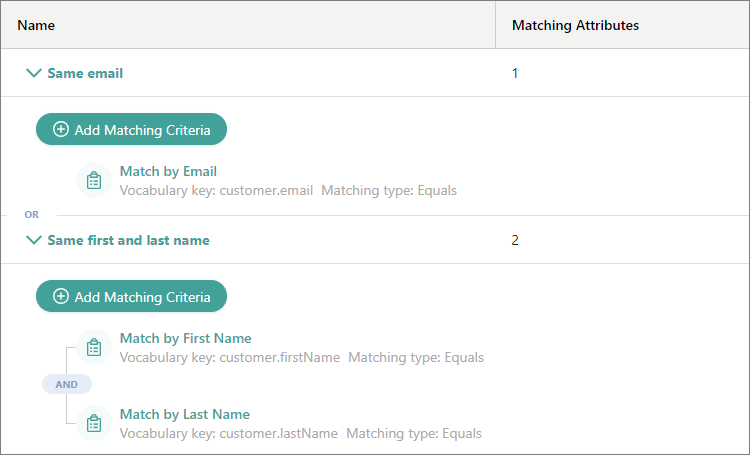
Matching rules allow you to set up complex logic for detecting duplicates. In the deduplication project, matching rules are combined using the OR logical operator, while matching criteria within a rule are combined using the AND logical operator. So, if you want a record to be identified as a duplicate if it meets at least one of your criteria, then you need a separate rule for each criteria. On the other hand, if you want a record to be identified as a duplicate if it meets all of your criteria, then you need one rule that includes all of your criteria.
For example, in the following configuration, either records with the same email address or records with the same first and last name are identified as duplicates.
Matching functions
Matching functions specify how values of a vocabulary key or property should be compared. The following table provides the description of matching functions.
| Function | Description |
|---|---|
| Equals | Identifies records as duplicates if two values are the same. |
| Fuzzy match - Sift4 | Detects approximate duplicates using a string similarity algorithm. This algorithm takes into account the number of matching characters and the transpositions (swaps) needed to make the strings identical. For example, algorithm and algorrithm would be identified as fuzzy matches.In this method, you have to specify the threshold— a parameter that sets the maximum number of characters by which two strings can differ and still be considered a match. |
| Fuzzy match - phonetic, DoubleMetaphone | Detects approximate duplicates using a phonetic matching algorithm. This algorithm encodes words into a phonetic representation, allowing for matching based on pronunciation rather than spelling. For example, night and knight would be identified as fuzzy matches. |
| Contains | Matches two values if one contains the other. |
| Starts with | Matches two values if one starts with the other. |
| Ends with | Matches two values if one ends with the other. |
| First token equals | Extracts the first word from both values and compares for exact match ignoring casing. |
| Matches two email address values if they are semantically equal. |
A matching function only defines how the two values of a single criterion are compared—it does not decide on its own whether two records are duplicates. Remember that matching criteria within a rule are combined with AND, and rules are combined with OR. A function such as First token equals is therefore most reliable when used as one criterion alongside others (for example, combined with a matching phone, email, domain, or country).
Watch the following video where we provide an explanation of matching functions along with practical examples.
The following sections describe each matching function in more detail, including how the values are compared and when to use the function.
Equals
Equals is the strictest matching function. It compares the two values using an exact, case-sensitive, culture-insensitive (ordinal) comparison. If both values are empty, they are not considered a match.
| Value 1 | Value 2 | Match? |
|---|---|---|
ABC | ABC | Yes |
ABC | abc | No (case-sensitive) |
"" | "" | No (empty values never match) |
Use Equals for identifiers, codes, exact normalized values, or any field where differences in casing should matter. If you want casing or formatting to be ignored, apply the appropriate normalization rules first.
Fuzzy match - Sift4
Fuzzy match - Sift4 is the typo-tolerant string matcher. It calculates a Sift4 similarity distance between the two values, converts it into a similarity score, and returns a match only when the score is greater than the configured threshold. You specify this threshold as a percentage (0–100) in the matching criterion configuration.
| Value 1 | Value 2 | Match? |
|---|---|---|
algorithm | algorrithm | Yes (with a suitable threshold) |
Microsoft | Microsofft | Likely, depending on the threshold |
Microsoft | Contoso | No |
This function measures string similarity, not semantic equality, so higher thresholds produce safer, more precise matches. Avoid using Sift4 on email addresses, where it tends to create false positives—use the Email function instead.
Fuzzy match - phonetic, DoubleMetaphone
Fuzzy match - phonetic, DoubleMetaphone compares how values sound rather than how they are spelled. It generates DoubleMetaphone phonetic keys for both values and considers them a match when their primary phonetic keys match, or when the primary and alternate keys cross-match.
| Value 1 | Value 2 | Match? |
|---|---|---|
night | knight | Yes |
Smith | Smyth | Yes |
John | Jane | No (do not trust just because both are names) |
Use this function for names where spelling variations are common. Avoid using it on identifiers, email addresses, or structured codes.
Contains
Contains is a bidirectional, case-insensitive substring matcher. After rejecting empty or too-short values, it returns a match when either value contains the other.
| Value 1 | Value 2 | Match? |
|---|---|---|
Acme Corporation | acme | Yes |
International Business Machines | business | Yes |
Acme | Contoso | No |
Contains is useful for company-name variants, but it can produce weak matches for short tokens. Configure a sensible minimum length, or normalize and tokenize the values, to reduce false positives.
Starts with
Starts with is bidirectional and case-insensitive. It returns a match when either value starts with the other.
| Value 1 | Value 2 | Match? |
|---|---|---|
CluedIn ApS | cluedin | Yes |
Microsoft Corporation | Microsoft | Yes |
Northwind Trading | Trading | No |
This function is useful when one source stores a shortened prefix and another stores the full value. Be cautious with common leading words such as The, New, or Global—handle these with normalization and a minimum length to avoid weak matches.
Ends with
Ends with mirrors Starts with but compares suffixes. It is bidirectional and case-insensitive, returning a match when either value ends with the other.
| Value 1 | Value 2 | Match? |
|---|---|---|
Acme Ltd | ltd | Yes |
Example Incorporated | incorporated | Yes |
Acme Ltd | Acme | No |
This function is useful for suffix-based matching. However, for legal company suffixes such as Ltd, ApS, Inc, or GmbH, normalization is usually safer than relying on Ends with alone, because many unrelated companies share the same suffix.
First token equals
First token equals splits each value on a space and compares only the first token, ignoring case.
| Value 1 | Value 2 | Match? |
|---|---|---|
John Smith | john Doe | Yes (both first tokens are John) |
Acme Denmark | acme Sweden | Yes |
John Smith | Jane Smith | No |
Because it ignores everything after the first token, this function is intentionally narrow and can be risky on its own. It works best as one criterion inside an AND rule—for example, first token equals combined with a matching phone, email, domain, or country. The function only splits on a space, so any cleanup such as trimming punctuation or collapsing whitespace should be done with normalization rules.
Email is email-aware equality rather than typo-tolerant matching. After rejecting empty values, it first tries a case-insensitive comparison, and if both values are valid email addresses it compares them as email addresses. Exact email addresses are treated as equal regardless of case. For Gmail addresses specifically, the local part is normalized by removing dots and stripping any +alias text before comparison.
| Value 1 | Value 2 | Match? |
|---|---|---|
MY@EMAIL.COM | my@email.com | Yes |
john.smith@gmail.com | johnsmith@gmail.com | Yes (Gmail ignores dots) |
john+crm@gmail.com | john@gmail.com | Yes (Gmail ignores +alias) |
john@company.com | jon@company.com | No |
Use Email for email fields instead of Fuzzy match - Sift4, because fuzzy matching email addresses is a common source of false positives.
Normalization rules
Normalization rules clean up values before comparing them to identify duplicates. The following table provides the description of normalization rules.
| Normalization rule | Description |
|---|---|
| To lowercase | Converts values to lover case. |
| Trim whitespace | Removes whitespace characters from values. |
| Remove punctuation | Removes punctuation marks from the values. For example, CluedIn.!?, will be converted to CluedIn. |
| Remove special characters | Removes special characters from the values. For example, CluedIn”#€%&(/)€ will be converted to CluedIn. |
| Remove diacritic marks | Removes diacritic marks from the values. For example, spăn'ĭsh will be converted to spanish. |
| Person name variations | Generates person name variations. For example, Timothy Daniel Ward will be converted to Tim D. Ward, Tim Ward. |
| First name nickname variants | Generates nickname variations for the person’s first name. For example, Timothy will be converted to Tim, Timmy. |
| Organization name | Normalizes organization name. For example, CluedIn ApS will be converted to CluedIn. |
| Organization name postfix | Strips company suffixes/postfixes and handles “trading as” splits. For example, Company Name Inc. will be converted to company name. A narrower, cheaper alternative to Organization name when you only need suffix removal. |
| Phone number | Removes well-known phone number formatting characters. For example, +45-123 456 789 (001) will be converted to 45123456789001. |
| Email mask | Normalizes email address to match other variants. |
| Street address | Normalizes common street name tokens. |
| Geography country | Converts country to ISO code. For example, Australia will be converted to AU. |
| Replace text | Replaces text using configured pattern. You need to enter both the value to be replaced and the replacement value. |
| Regex replace text | Replaces text using configured regex pattern. |
| Split text | Splits text using configured separator. |
| Regex split text | Splits text using configured regex separator pattern. |
| Split text by whitespace | Splits text by whitespace into tokens. |
| Transliterate | Transliterates text value to an ASCII string. For example, Ελληνική Δημοκρατία will be converted to Ellēnikē Dēmokratia. |
Normalization rules are applied before matching, so they do not decide duplicates by themselves. Instead, they transform one or more input values into comparison candidates that are then passed to the matching functions.
Keep two behaviors in mind:
- Single-value rules emit nothing when there is no change. If the transformed value is identical to the input, or the result is empty, no normalized value is emitted (the result becomes null). Normalization only contributes a candidate when it actually changes the value.
- Multi-value rules can emit several candidates. Rules such as token splitters or name-variation generators produce multiple comparison candidates from a single input. Normalization therefore expands and cleans candidate values—it is not always a simple one-input/one-output operation.
Watch the following video where we provide an explanation of normalization rules along with practical examples.
The following sections describe each normalization rule in more detail, including how the values are transformed and when to use the rule.
To lowercase
Converts the value to its invariant (culture-independent) lowercase form.
| Input | Normalized value |
|---|---|
CLuedIn | cluedin |
JOHN.SMITH@EXAMPLE.COM | john.smith@example.com |
München | münchen |
Use this rule when casing should not matter. It is usually safe for names, email addresses, organization names, and codes where case has no semantic meaning.
Trim whitespace
Normalizes whitespace by replacing runs of separator, whitespace, newline, and tab characters with a single space, then trimming the ends.
| Input | Normalized value |
|---|---|
␣Acme Ltd␣ | Acme Ltd |
John⇥Smith | John Smith |
A↵B | A B |
This is a low-risk normalizer. It is usually a good idea to apply it before exact or fuzzy comparisons on human-entered text.
Remove punctuation
A multi-value normalizer rather than a simple cleanup. It emits one variant where punctuation is replaced by spaces (and collapsed), and another variant where punctuation is removed entirely—when that joined variant differs from the spaced one.
| Input | Normalized candidates |
|---|---|
Acme-Ltd | Acme Ltd, AcmeLtd |
CluedIn.!?, | CluedIn |
A/B Test | spaced variant and joined variant |
This can improve matching, but it can also broaden matches. Pair it with stronger criteria when punctuation is meaningful.
Remove special characters
Broader than Remove punctuation: it replaces punctuation, Unicode separators, symbols, “other number” characters, and whitespace with spaces, then trims and collapses repeated spaces.
| Input | Normalized value |
|---|---|
CluedIn”#€%&(/)€ | CluedIn |
A+B=C | A B C (approximately) |
ACME™ Ltd | ACME Ltd |
Because it also removes symbols, do not apply it blindly to values where symbols carry meaning, such as product SKUs.
Remove diacritic marks
Strips accents and diacritics from the value.
| Input | Normalized value |
|---|---|
spăn'ĭsh | spanish |
München | Munchen |
José | Jose |
This is useful for names, cities, and organizations coming from systems with inconsistent accent handling. It is not transliteration for non-Latin scripts—it only removes diacritic marks. For non-ASCII scripts, use Transliterate.
Person name variations
Generates multiple person-name candidates from a single name. It parses the name and can emit a FirstName LastName form, the parser’s full name, a middle-initial form for three-part names, and nickname-plus-last-name variants when the nickname model is available. It also applies punctuation removal and transliteration as part of generating variations.
| Input | Normalized candidates |
|---|---|
Timothy Daniel Ward | Timothy Ward, Timothy Daniel Ward, Timothy D. Ward, and nickname forms such as Tim Ward or Timmy Ward (depending on the nickname model) |
This rule is powerful but too loose to use alone. Combine it with a stable field such as last name, email, phone, or address.
First name nickname variants
Narrower than Person name variations. It looks up nicknames for a single first-name value and returns those nicknames along with the original value.
| Input | Normalized candidates |
|---|---|
Timothy | Timothy, Tim, Timmy |
William | William, Will, Bill, … (depending on the model data) |
Apply this to a first-name field, not a full-name field—otherwise the output will be poor.
Organization name
The broader organization-name normalizer. It lowercases and pre-trims noisy leading/trailing characters, removes invalid values, applies a large chain of replacements, strips organization postfixes, converts encoded hex bytes to Unicode, applies exact-match pre-normalization, transliterates, and can split “trading as” style names.
| Input | Normalized candidates |
|---|---|
CluedIn ApS | cluedin |
Foo Ltd / Bar GmbH | separate organization candidates |
ACME t/a Widgets Ltd | acme and Widgets-style variants |
This is a broad normalizer and works best in combination with other criteria such as country. If you only need suffix removal—especially for large deduplication jobs—use Organization name postfix instead.
Organization name postfix
The narrower normalizer that strips company suffixes/postfixes and handles “trading as” splits.
| Input | Normalized candidates |
|---|---|
Company Name Inc. | company name |
CluedIn ApS | cluedin |
ABC Ltd trading as XYZ | split candidates around the “trading as” marker |
This is usually safer and cheaper than the full Organization name normalizer when the main issue is legal suffix variation such as Ltd, Inc, GmbH, or ApS.
Phone number
A simple formatting stripper. It removes +, hyphens, underscores, whitespace, and parentheses.
| Input | Normalized value |
|---|---|
+45-123 456 789 (001) | 45123456789001 |
(555) 123-4567 | 5551234567 |
+1 212 555 0100 | 12125550100 |
It does not parse country codes or validate phone numbers; it only removes common formatting characters. Do not treat it as full E.164 normalization.
Email mask
Normalizes email addresses into comparable masks. It only processes valid email addresses and filters out configured provider/domain values. Gmail addresses are handled specially (normalizing the Gmail user), while for other addresses the host is mapped to the parsed registrable domain with a .dummy suffix.
| Input | Normalized value |
|---|---|
john.smith+crm@gmail.com | johnsmith@gmail.com (Gmail-normalized) |
jane@sub.company.com | jane@company.dummy |
| invalid email | ignored |
This is useful when domains/subdomains or Gmail aliases differ. Use it carefully on shared or generic inboxes.
Street address normalization
Street address normalization converts input addresses into standardized versions before comparing them to identify duplicates.
Before applying the token replacements, the rule lowercases the value, replaces hyphens with spaces, removes :, ,, and #, removes the phrase ` lower level , and trims whitespace. It then applies the table of common street and address token replacements below. This is token-based replacement, not full postal-address parsing—for example, 5 Main Rd. normalizes toward 5 main [RD], and PO Box 123 normalizes toward [POBOX] 123`.
For example, let’s consider two addresses: 123 Fantasy strabe and 123 Fantasy street. When street address normalization is selected, any time CluedIn sees strabe, strasse, street, or str, it turns it into [STR]. If the only thing that differs in an address is the way street is spelled, then the addresses will match.
| Input | Normalized version |
|---|---|
strabe, strasse, street, str\.?, st | [STR] |
Allee, aly | [ALY] |
Boulevard, BLVD | [BLVD] |
Lane, Ln | [LANE] |
Drive, Dr | [DRIVE] |
avenue, ave | [AVE] |
University, univ | [UNIVERSITY] |
West, w | [WEST] |
North, n | [NORTH] |
East, e | [EAST] |
South, s | [SOUTH] |
Floor, flr | [FLOOR] |
First, 1st | [1ST] |
Second, 2nd, 2rd | [2ND] |
Third, 3rd | [3RD] |
Fourth, 4th | [4TH] |
Fifth, 5th | [5TH] |
p\.?\s*o\.?\s+box, post\s*box, post\s*boks, GPO\s*Box | [POBOX] |
Private\sbag, Locked\sBag, Private\sMail\sBag, Locked\sBag, PMB | [PMB] |
Plaza, PLAZ, PLZ | [PLZ] |
Suite, STE | [STE] |
Trailer, TRLR | [TRLR] |
Apartment, APT | [APT] |
Basement, BSMT | [BSMT] |
Building, BLDG | [BLDG] |
Department, DEPT | [DEPT] |
Hanger, HNGR | [HNGR] |
Lobby, LBBY | [LBBY] |
Lower, LOWR | [LOWR] |
Office, OFC | [OFC] |
Penthouse, PH | [PH] |
Space, SPC | [SPC] |
Level, LVL | [LEVEL] |
Highway, Highwy, Hiway, Hiwy, Hway, Hwy | [HWY] |
Geography country
Normalizes a country value to its ISO country code. It first tries to resolve the input to an ISO code, and falls back to an alternative country-normalization method if that does not succeed.
| Input | Normalized value |
|---|---|
Australia | AU |
United States | US |
DK | DK or Denmark (depending on the model) |
This is the right normalizer for country fields, typically used before comparing with Equals.
Replace text
A configurable, case-insensitive literal string replacement. It requires the value to replace (oldValue) and accepts an optional replacement value (newValue); when no replacement is provided, the matched text is removed.
| Configuration | Input | Normalized value |
|---|---|---|
oldValue = "Limited", newValue = "Ltd" | Acme Limited | Acme Ltd |
oldValue = "-", empty replacement | AB-123 | AB123 |
Use this when you know the exact literal cleanup you want.
Regex replace text
The regular-expression version of Replace text. It requires a regex pattern and accepts an optional replacement, validates the pattern, performs a case-insensitive replacement, then collapses repeated spaces and trims.
| Configuration | Input | Normalized value |
|---|---|---|
pattern \bcorp\.?\b, replacement corporation | Acme Corp. | Acme corporation |
pattern [^0-9], empty replacement | +45 123-456 | 45123456 |
This is flexible but easy to over-broaden—a poorly scoped pattern can create bad deduplication groups quickly.
Split text
Configurable tokenization using a literal separator. It requires a separator, splits the value on it, removes empty entries, trims each token, and emits the non-empty tokens. If one of the tokens matches, the value is considered a match, so this is useful for multi-valued fields packed into a single string.
| Configuration | Input | Normalized candidates |
|---|---|---|
separator ; | a@x.com; b@y.com | a@x.com, b@y.com |
separator \| | ABC\|DEF | ABC, DEF |
Regex split text
Tokenization using a regex separator pattern. It requires the pattern, validates it, splits case-insensitively, trims each token, and emits the non-empty tokens.
| Configuration | Input | Normalized candidates |
|---|---|---|
pattern [,;\|] | a,b;c\|d | a, b, c, d |
pattern \s+/\s+ | Foo / Bar | Foo, Bar |
Use this where the delimiter varies or is more complex than a single literal separator.
Split text by whitespace
Emits the distinct whitespace-separated tokens of a value, optionally filtered by a minimum token length. When configured, the minimum token length must be greater than 1; the rule splits on whitespace, removes duplicates, and then filters by length if a minimum is set.
| Configuration | Input | Normalized candidates |
|---|---|---|
| (no minimum) | Acme North Europe | Acme, North, Europe |
| minimum length 4 | Acme North UK | Acme, North (drops UK) |
This can help with loose matching, but it is risky on common words unless combined with other criteria.
Transliterate
Converts a value to an ASCII string, trims the result, and removes apostrophes.
| Input | Normalized value |
|---|---|
Ελληνική Δημοκρατία | Ellenike Demokratia (approximately) |
北京市 | romanized ASCII approximation |
O’Connor | OConnor |
Use this when data mixes scripts or contains non-ASCII names that should be compared against ASCII representations. For simple accents only, Remove diacritic marks is the narrower choice.
Deduplication project
This section contains reference information about deduplication project statuses.
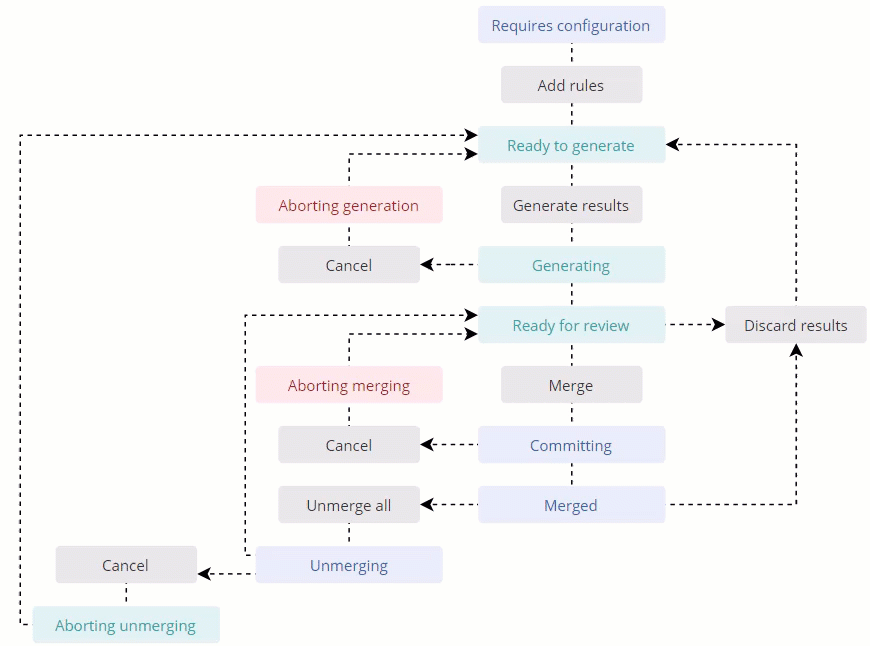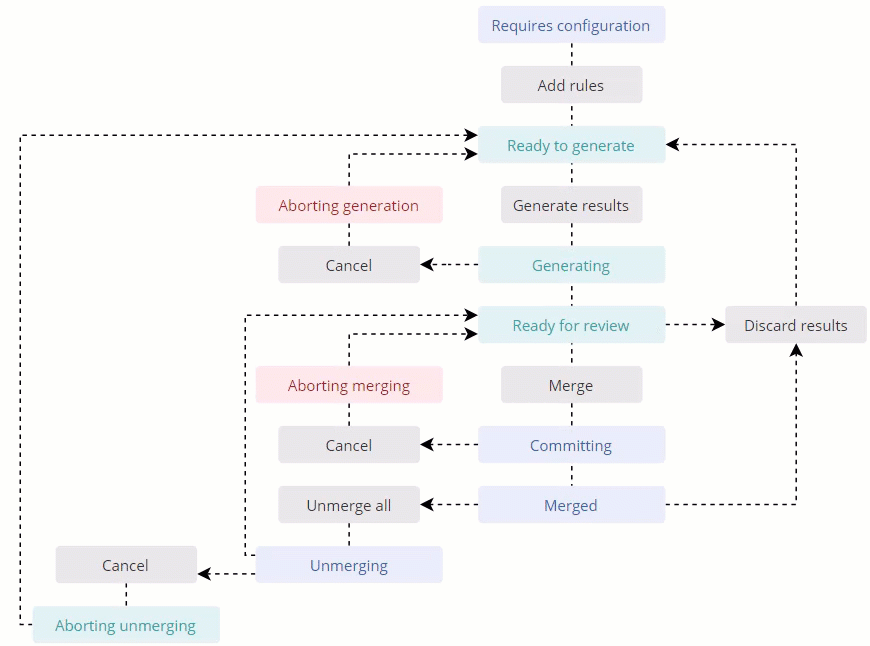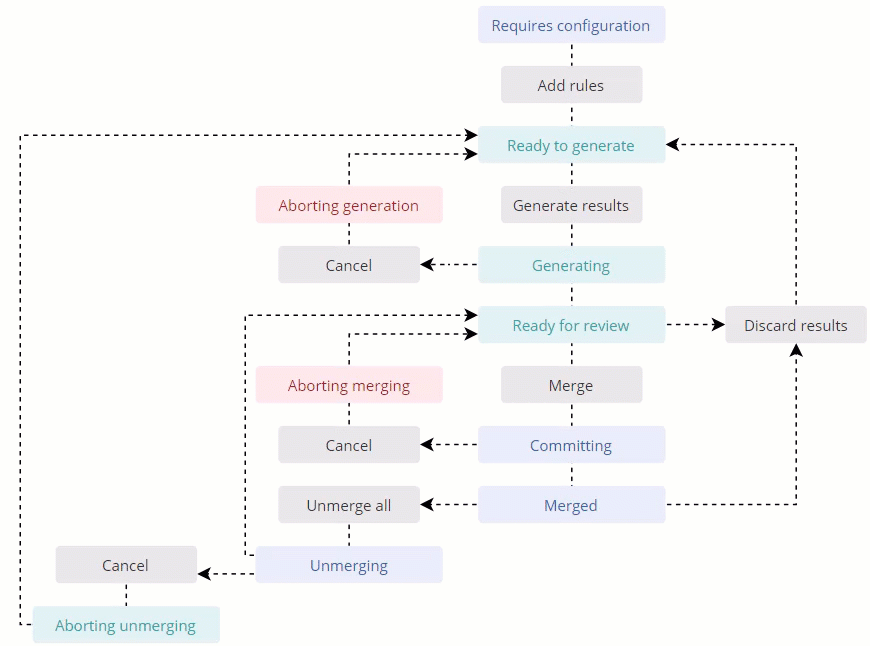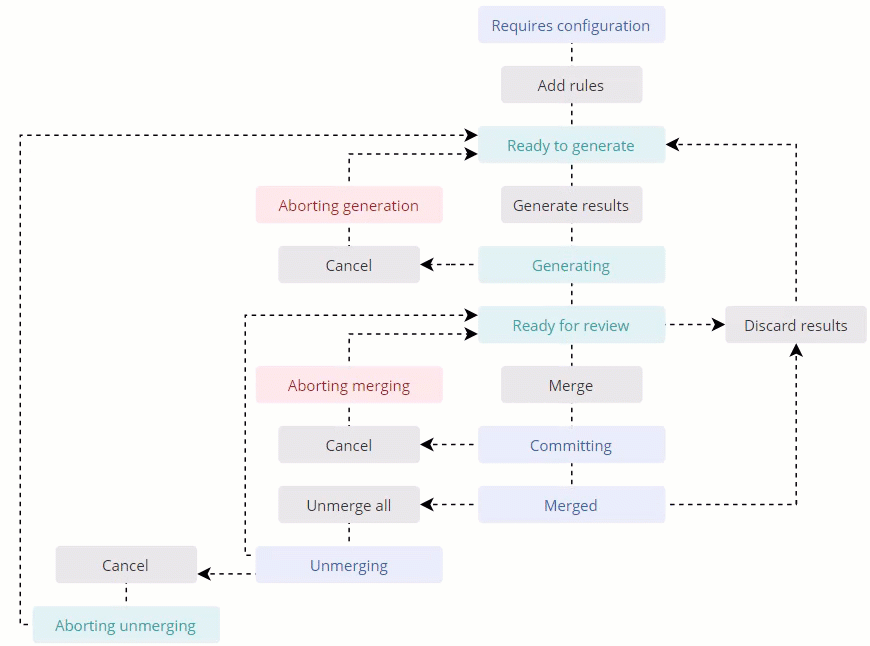
Project statuses
The following table provides descriptions of deduplication project statuses.
| Status | Description |
|---|---|
| Requires configuration | The deduplication project has been created, no matching rules have been added yet. |
| Ready to generate | The deduplication project has been configured, no matches have been generated yet. This status also appears when you discard matches at any further stage of the project. |
| Generating | CluedIn is analyzing the specified set of golden records with the aim to detect duplicates based on your matching rules. |
| Aborting generation | The process of generating matches of the deduplication project is being cancelled. The status will shortly change to Ready to generate. |
| Ready for review | CluedIn has generated matches of the deduplication project, you can start processing groups of duplicates. |
| Committing | CluedIn is merging records from selected groups. This status is applicable whether you are merging a single group, multiple groups, or all groups in the project. |
| Merged | CluedIn has merged records from all groups in the project. If the project contains groups that were not selected for merge, the project status remains Ready for review. |
| Unmerging | CluedIn is reverting the results of merge. When records are unmerged, the project status becomes Ready for review. |
| Abort unmerging | The process of reverting changes is being cancelled. The status will shortly change to Ready to generate. |
Project status workflow
The following diagram shows the deduplication project workflow along with its statuses and main activities.
Group of duplicates
This section contains reference information about the statuses of a group of duplicates.
Group statuses
The following table provides descriptions of the statuses of groups of duplicates.
| Status | Description |
|---|---|
| New | The group with potential duplicates has been generated. This status is also applicable when you revoke the group’s approval. |
| Approved | The group has been approved and it is ready for merge. If you change your mind, you can reject the group. If you are uncertain about the selection of values in the group, you can revoke your approval and start processing the group from scratch. |
| Rejected | The group has been rejected and it cannot be merged. If you change your mind, you can approve the group. |
| Merge Committed | The group has been merged. When all groups in the project have this status, the status of the project becomes Merged. If you are not satisfied with the merged golden record, you can revert the changes by unmerging the records. |
| Unmerged | The changes made to the golden record through merging have been reverted, restoring duplicate records to their previous state before the merge. |
Group status workflow
The following diagram shows the group of duplicates workflow along with its statuses and main activities.
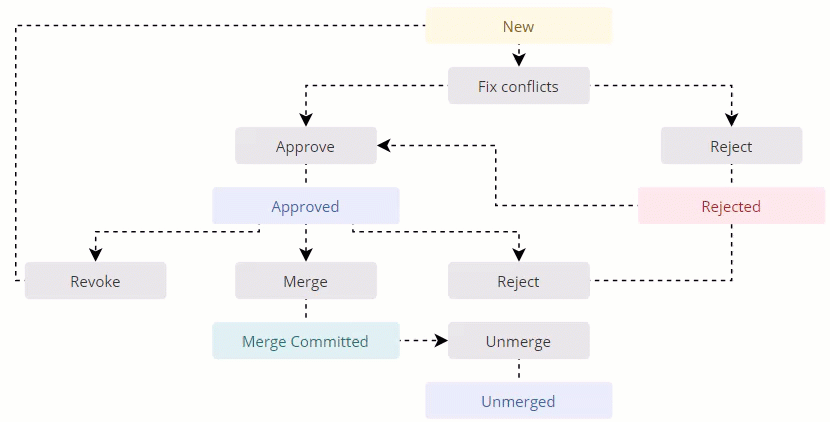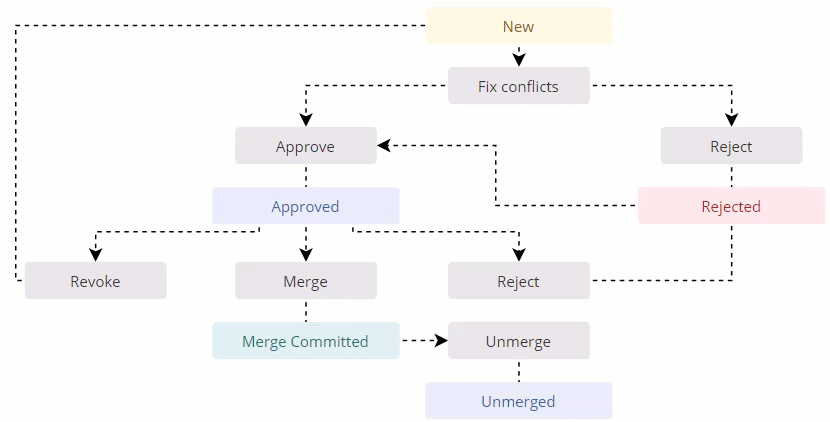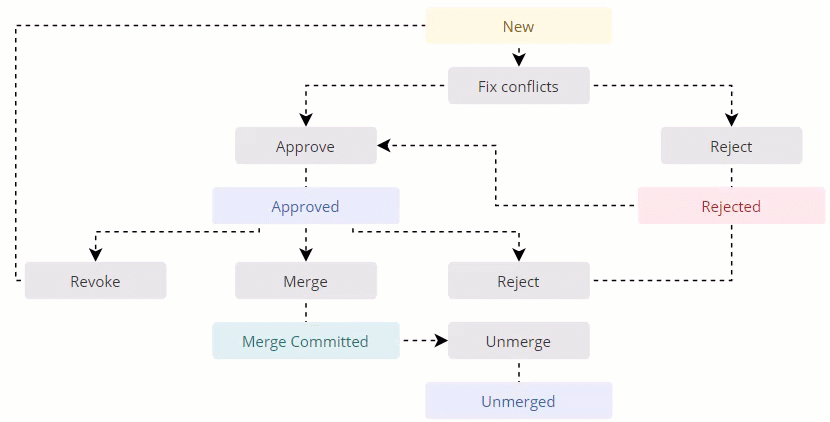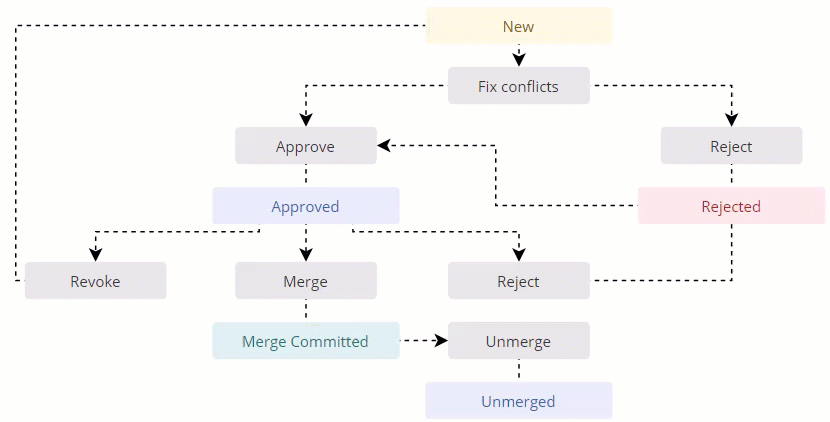
Deduplication project audit log actions
Whenever some changes or actions are made in the deduplication project, they are recorded and can be found on the Audit Log tab. These actions include the following:
- Create a deduplication project
- Add users to owners
- Update a deduplication project
- Create a deduplication rule
- Update a deduplication rule
- Activate a matching rule
- Deactivate a matching rule
- Generate matches
- Discard matches
- Manual conflict resolution
- Reset manual conflict resolutions
- Remove entity from a group
- Approve one group
- Approve multiple groups
- Approve all groups
- Remove (revoke) approval from all groups
- Remove (revoke) approval from groups (one or multiple groups)
- Reject groups (one or multiple groups)
- Merge groups (one or multiple selected groups)
- Merge approved groups
- Undo merged entities
- Undo merge groups
- Abort undo
- Cancel generating matches
- Cancel merge
- Archive a deduplication project