GraphQL
On this page
- How it works
- Supported operations
- Case sensitivity in lookups
- Enabling case-insensitive lookups
- Examples of using GraphQL
- Get an entity by ID
- Get entities by search
- Get entities by vocabulary keys
- Get entities by a combination of vocabulary keys
- Get all entities that have a value for a certain property
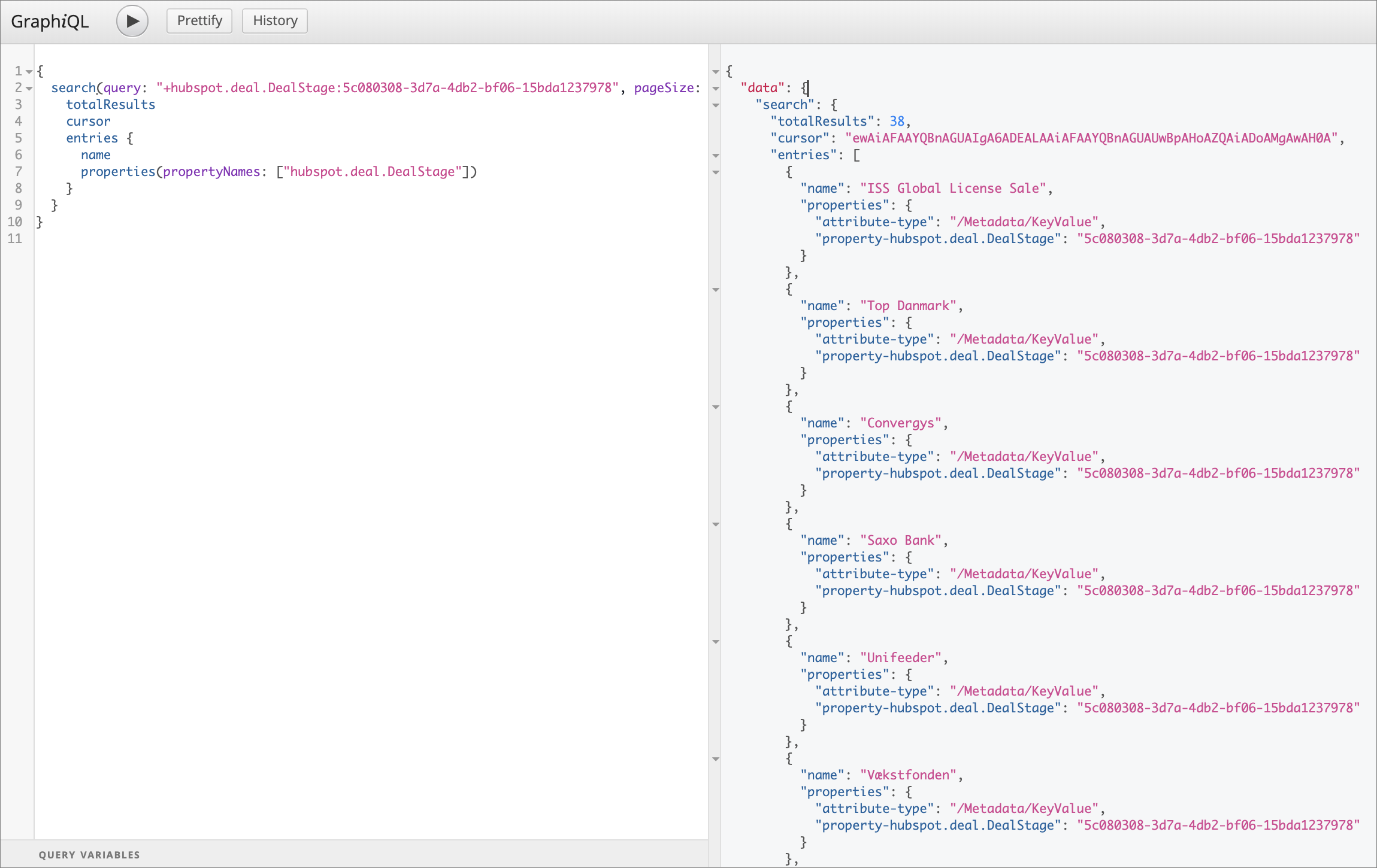
- Change what properties come back in the results, 4 records at a time
- Change what metadata comes out of the properties
- Explore edges
- Search for all golden records which comes from certain datasource
- Get all record which have failed lookup data
- Filter by Tags
- Filter “codes” via filters-array and then postProcess
CluedIn provides GraphQL as a flexible way to pull and query data. The CluedIn GraphQL endpoint integrates multiple datastores to service each query efficiently, using an internal query optimizer to determine which datastore should handle which part of the request.
How it works
Depending on the query, CluedIn may interact with one or more of the following datastores:
-
Search store – For full-text searches and property-based lookups.
-
Graph store – For exploring relationships and connected records.
-
Blob store – For retrieving complete record histories and raw data.
The query optimizer automatically selects the best datastore combination for each query.
Consider the following example:
-
A query that finds all entities in a specific business domain with a certain property value is handled entirely by the Search store.
-
If the query also requests the full history of those records, CluedIn first retrieves the results from the Search store, and then asks the Blob store for historical data.
-
If the query expands to include related records (for example, entities of the Person type connected to the results), CluedIn adds the Graph store to process that part of the query.
Supported operations
The CluedIn GraphQL endpoint supports a wide range of operations, including:
-
Get entities by ID.
-
Get entities using a full-text search.
-
Get entities by property value.
-
Get data metrics.
Case sensitivity in lookups
By default, all value lookups are case-sensitive. For example, organisation.industry:Banking will not match entities where the value is “banking” (lowercase “b”).
While you can modify this behavior, CluedIn encourages using CluedIn Clean to normalize and standardize data values. This ensures that downstream consumers receive consistent data (for example, “Banking” vs “banking”) without requiring schema or query adjustments.
You can standardize capitalization and formatting conventions without pushing changes back to the original source systems through the Mesh API.
Enabling case-insensitive lookups
If you need to enable case-insensitive searches, extend the built-in ElasticEntity model within CluedIn and add custom properties with their respective analyzers to support case-insensitive matching.
Examples of using GraphQL
To help you get familiar with CluedIn’s GraphQL implementation, the following examples illustrate common queries you can experiment with.
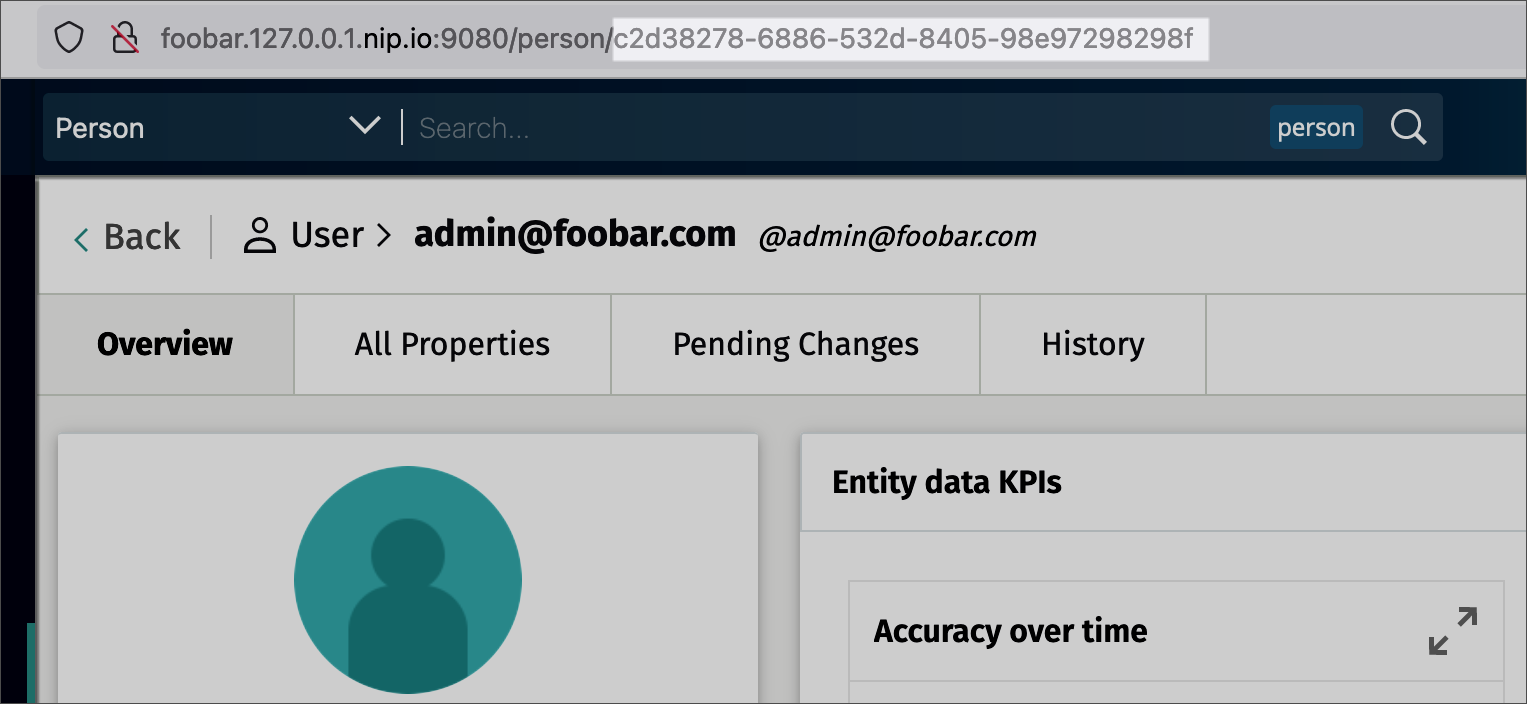
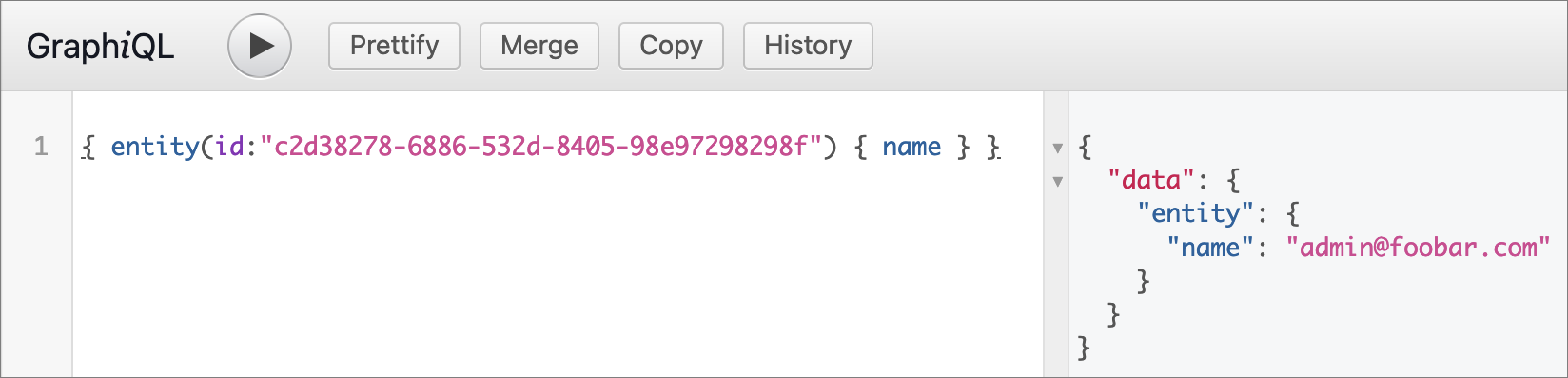
Get an entity by ID
You can retrieve a specific entity using its unique ID. To begin, you will need to obtain an example ID by searching for your admin user.
{
entity(id:"c2d38278-6886-532d-8405-98e97298298f")
{
name
}
}
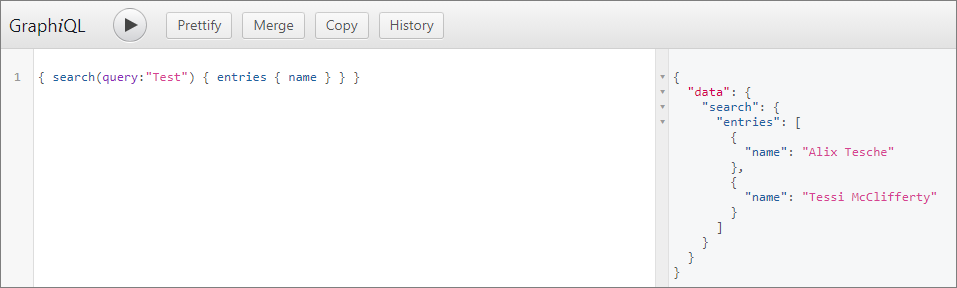
Get entities by search
{
search(query:"Test")
{
entries
{
name
}
}
}
Get entities by vocabulary keys
{
search(query:"properties.user.firstName:Alix")
{
entries
{
name
}
}
}
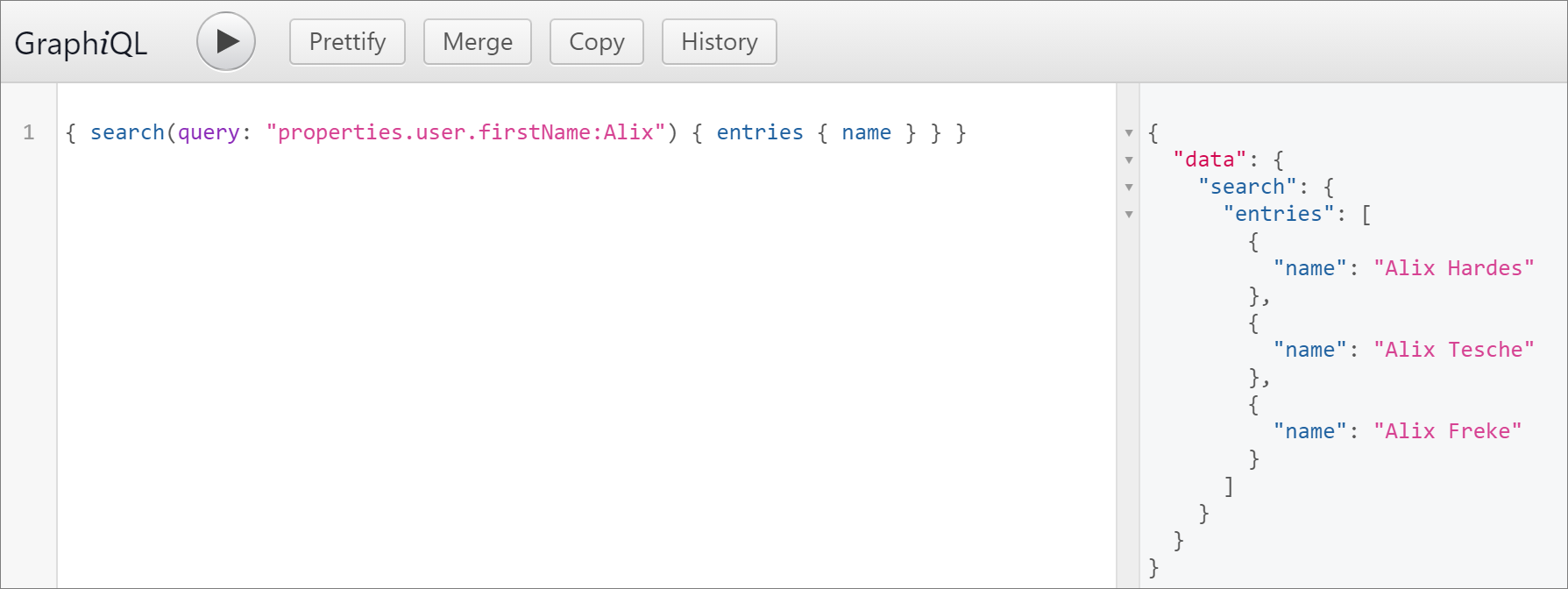
Get entities by a combination of vocabulary keys
{
search(query: "+properties.user.firstName:Alix +properties.user.lastName:Freke")
{
entries
{
name
}
}
}
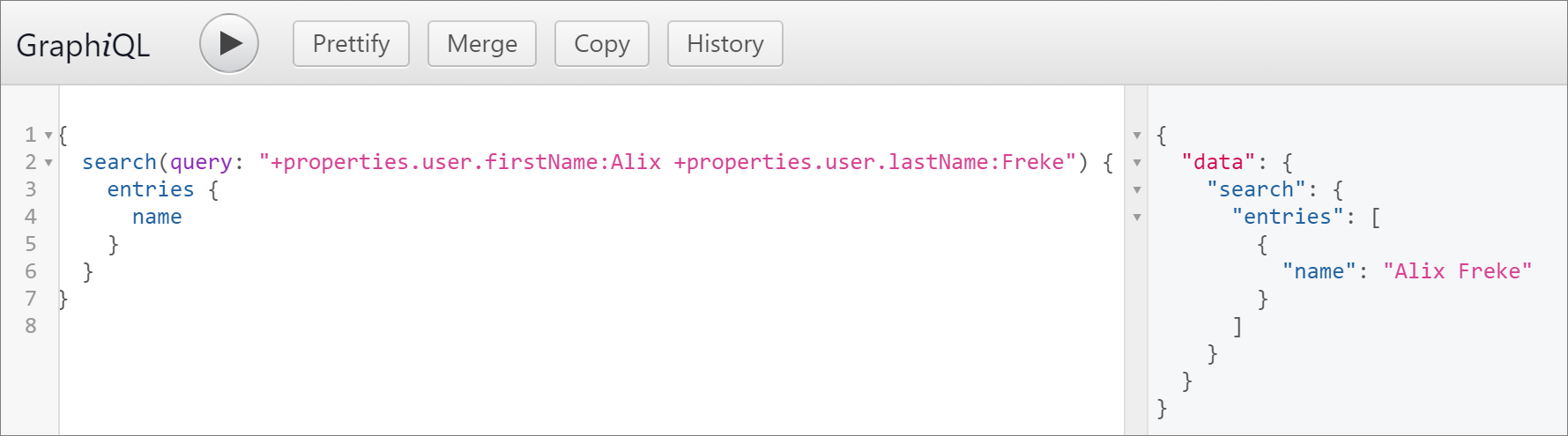
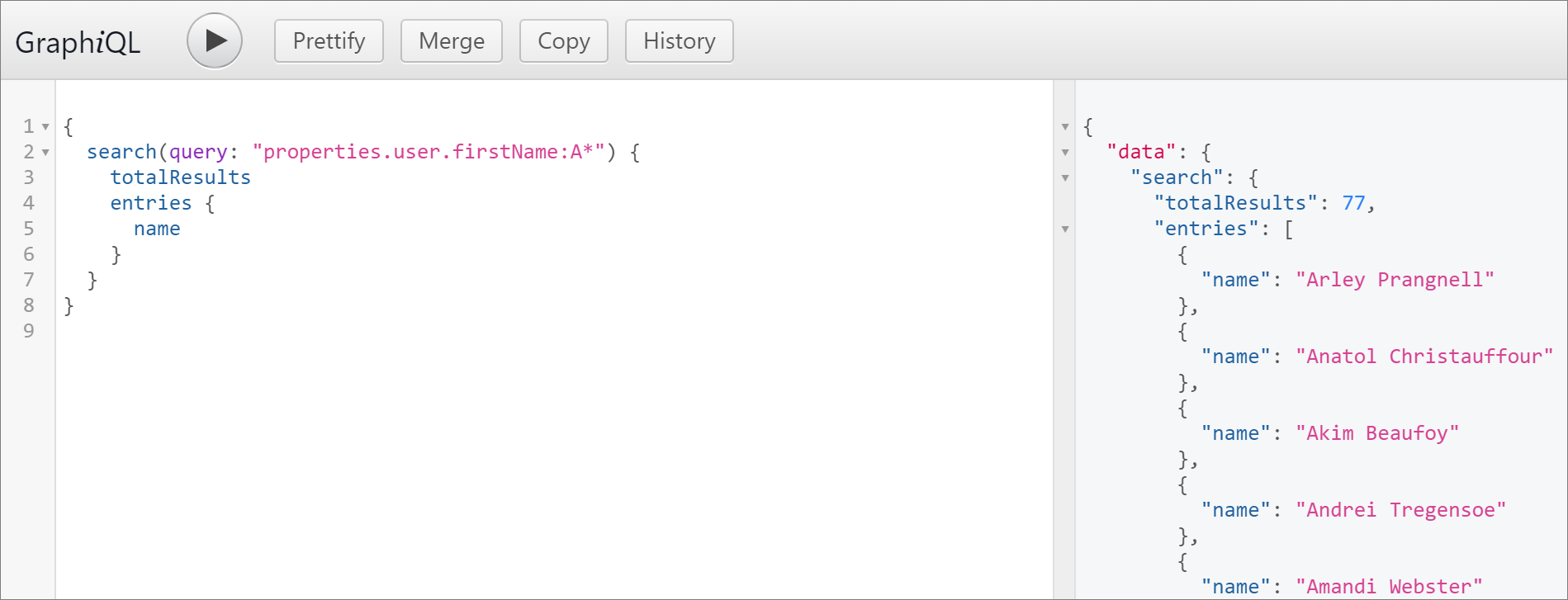
Get all entities that have a value for a certain property
{
search(query: "properties.user.firstName:A*")
{
totalResults
entries
{
name
}
}
}
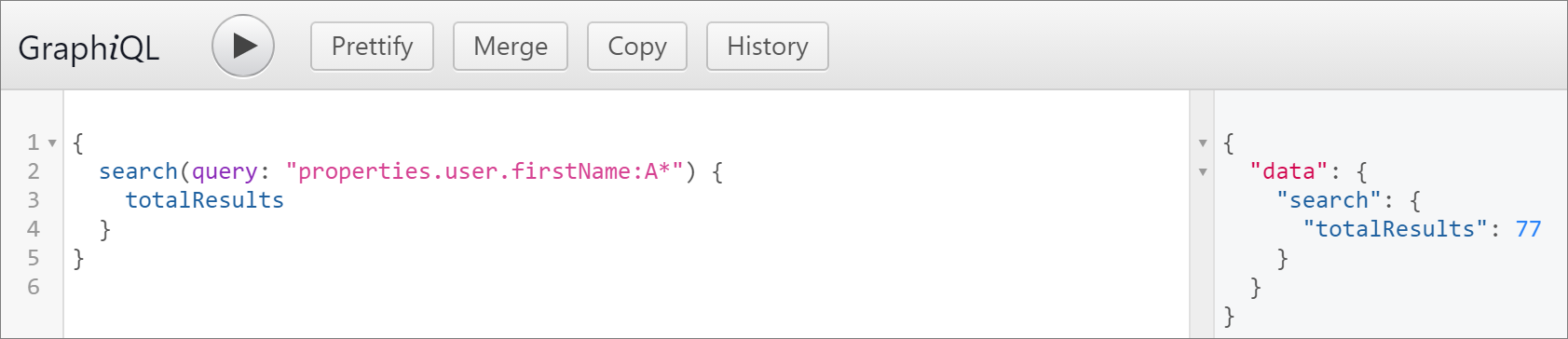
Alternatively, find out how many records match.
{
search(query: "properties.user.firstName:A*")
{
totalResults
}
}
Change what properties come back in the results, 4 records at a time
{
search(query: "properties.user.firstName:A*", pageSize:4)
{
totalResults
entries
{
name
createdDate
displayName
properties
}
}
}
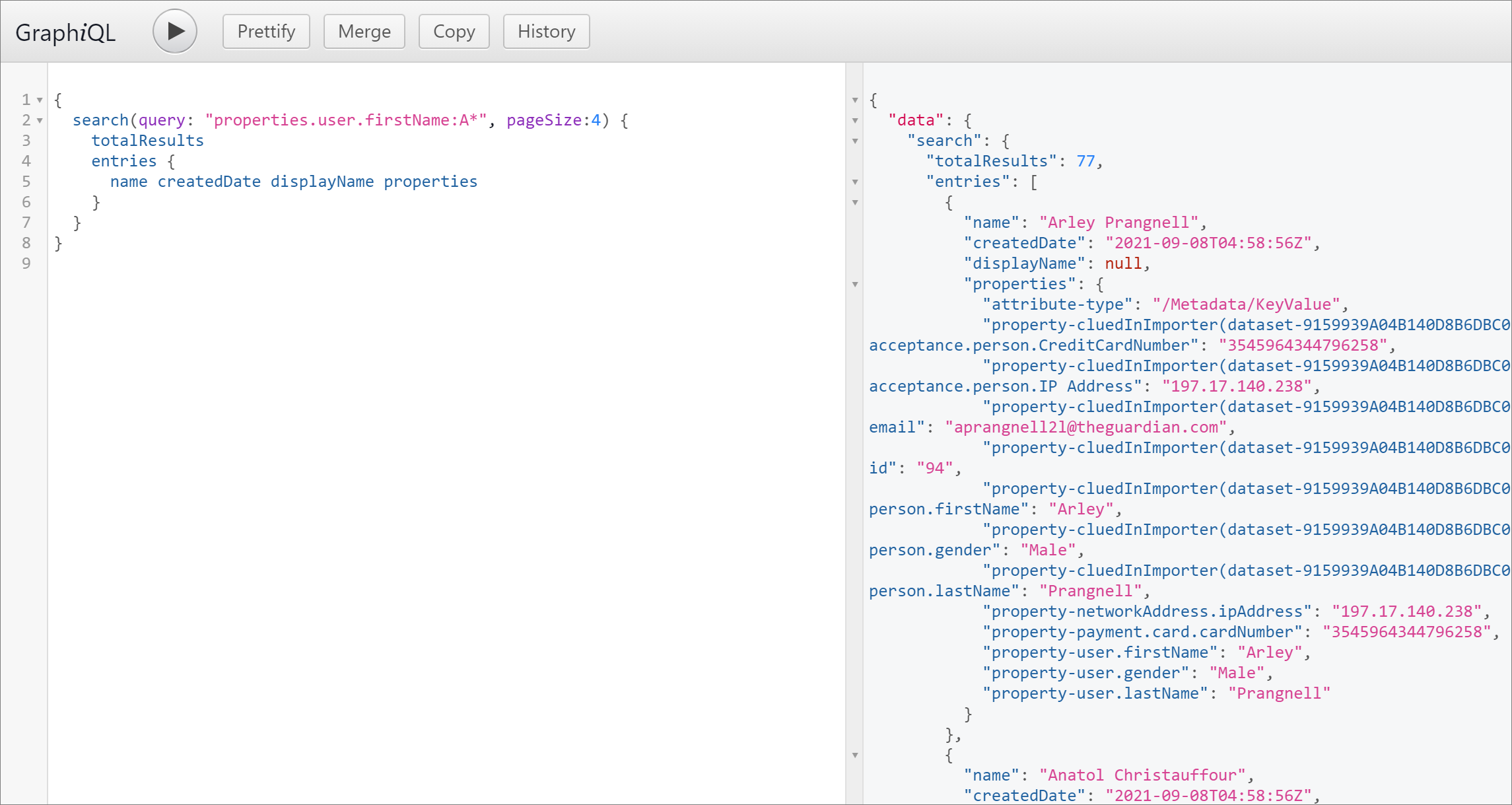
Change what metadata comes out of the properties
{
search(query: "properties.user.firstName:A*", pageSize:4)
{
totalResults
entries
{
name
properties(propertyNames:["user.lastName", "user.gender"])
}
}
}
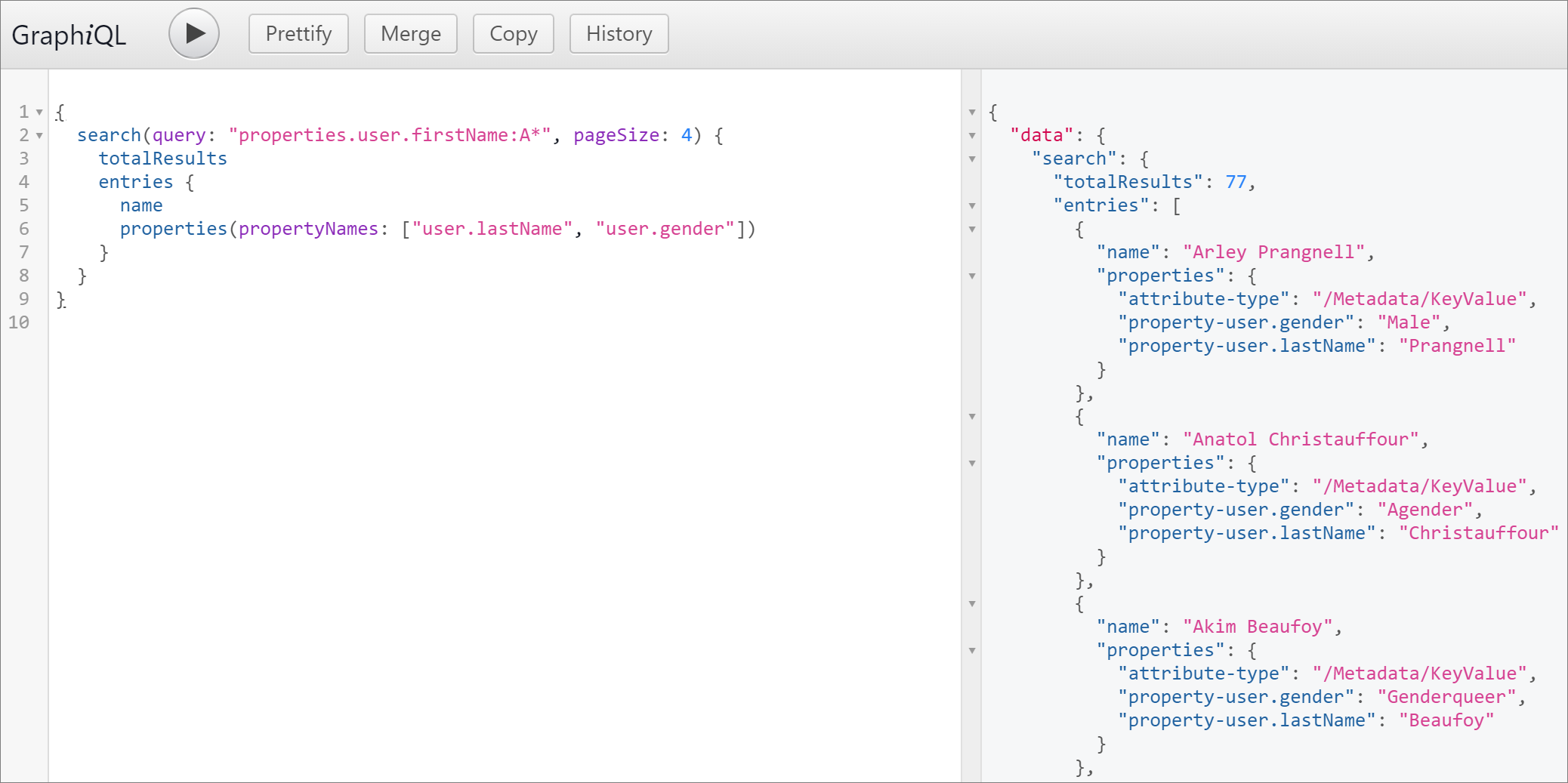
Explore edges
{
search(query: "user.firstName:*", pageSize: 4) {
entries {
name
edges {
outgoingOfType(entityType: "/Organization", edgeType: "/PartOf") {
entries {
name
}
}
}
}
}
}
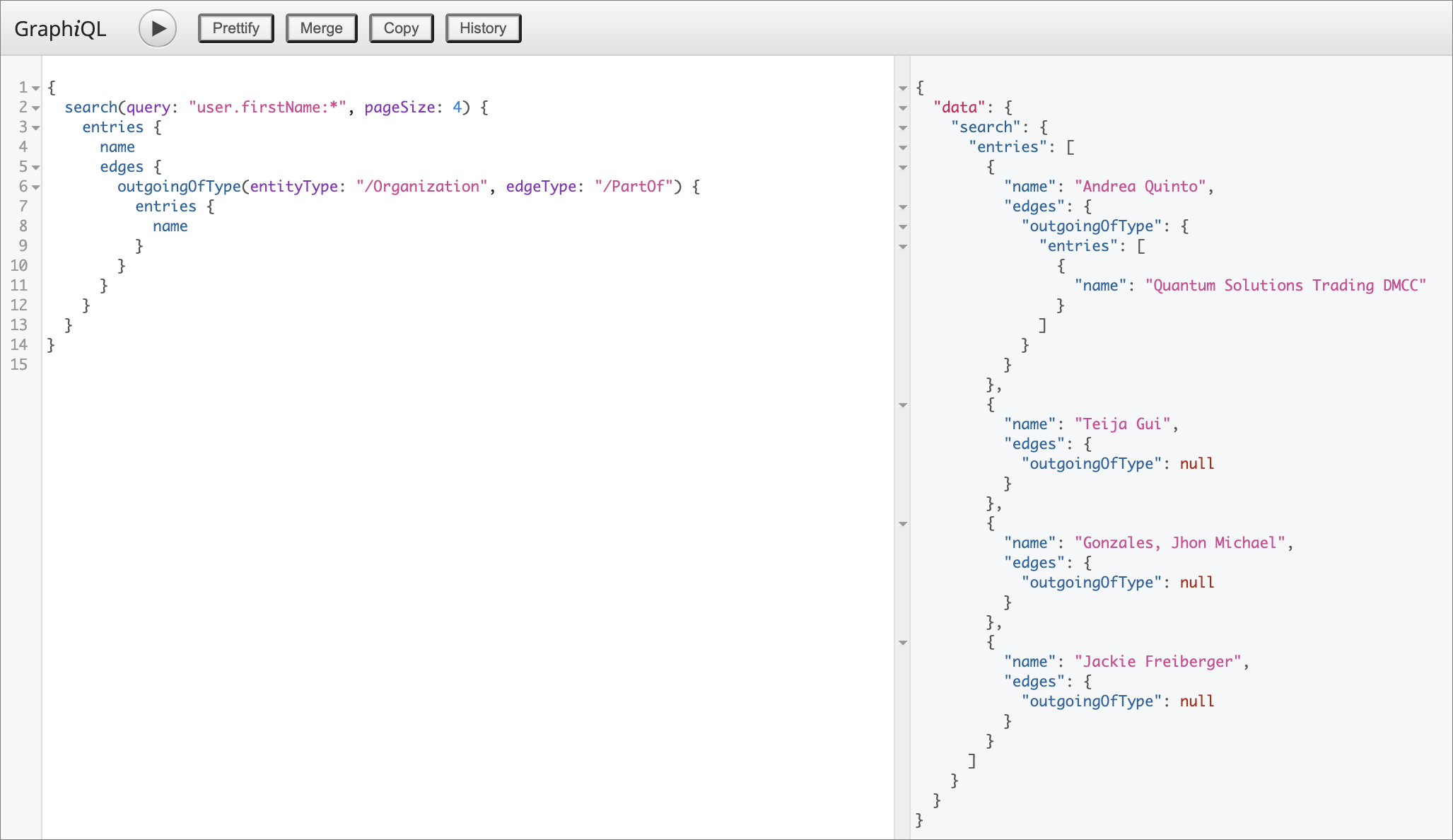
Search for all golden records which comes from certain datasource
Query
query searchQuery($query: String, $filters: [FilterQuery], $cursor: PagingCursor) {
search(
query: $query
filters: $filters
pageSize: 10000
cursor: $cursor
sort: FIELDS
sortFields: { field: "id", direction: ASCENDING }
) {
totalResults
cursor
entries {
id
name
entityType
properties
}
}
}
Variable
{
"query": "*",
"cursor": null,
"filters": [
{
"aggregationName": "providerDefinitionIds_v2",
"operator": "OR",
"values": [
"5158674b-7d18-4bb2-bb49-2e95c17f0b57"
]
}
]
}
Get all record which have failed lookup data
{
search(query:"+entityType:/FabricCompany +properties.fabriccompany.country-EntityCode:[Invalid*") {
totalResults
entries {
name
properties
}
}
}
Filter by Tags
query {
search(
query: "+entityType:/FabricCompany"
pageSize: 10000
filter: "tags:Invalid Validate that 'fabriccompany.country' contains ISO-2 coded country codes only, two uppercase letters."
) {
totalResults
entries {
tags
id
name
properties
}
}
}
Filter “codes” via filters-array and then postProcess
query {
search(
query: "+entityType:/FabricCompany"
pageSize: 10000
filters: [{
fieldName: "codes"
operator: OR
values: ["/FabricCompany#company:CluedIn(hash-sha1):a57b9dad98e2679de828ef1f4aced537534c600d"]
}]
) {
totalResults
entries {
id
name
properties
}
}
}