Release overview
On this page
- Release notes
- Release plan for 2025–2026
- Release plan for 2026-2027
- Featured roadmap items
- Agents Redesign
- MCP
- Agents can write deterministic code
- Performance UI/UX updates
- Processing Pipeline Update
- Jobs Monitor
- OpenTelemetry
- Moving Blobs to Blob Storage
- Data Contracts
- Streams V3
- Export Targets receipts
- Lookup AI resolution
- Duplicate Clusters AI loop
- Rule Inspector
- Cost of Running Lowering
- Topology Viewer 2
- Workflow Engine V3
- Release plan
- Roadmap timeline
- Release process
In this article, you will find links to release notes and learn about our release process and product versioning.
Release notes
This section includes links to release notes for the CluedIn platform as well as links to the releases of additional resources.
Latest release
| Version | Technical version | Release notes |
|---|---|---|
| 2026.02.00 | 4.8.0 | View release notes |
Previous releases
| Version | Technical version | Release notes |
|---|---|---|
| 2026.01.00 | 4.7.0 | View release notes |
| 2025.09.00 | 4.6.0 | View release notes |
| 2025.05.02 | 4.5.2 | View release notes |
| 2025.05.01 | 4.5.1 | View release notes |
| 2025.05.00 | 4.5.0 | View release notes |
| 2024.12.02 | 4.4.2 | View release notes |
| 2024.12.01 | 4.4.1 | View release notes |
| 2024.12 | 4.4.0 | View release notes |
| 2024.07 | 4.3 | View release notes |
| 2024.04 | 4.3.0 | View release notes |
| 2024.03 | 4.1.0 | View release notes |
| 2024.01 | 4.0.0 | View release notes |
| 2023.07 | View release notes | |
| 2023.04 | View release notes | |
| 2022.10 | View release notes | |
| 2022.06 | View release notes | |
| 3.3 | View release notes | |
| 3.2 | View release notes |
Releases of additional resources
| Resource | Description | Release |
|---|---|---|
| Home repo | Contains resources for the local installation of CluedIn. | View releases |
| Charts repo | Contains installation scripts to install CluedIn in Kubernetes. | View releases |
| Integrations releases | Contains releases of installation packages for enrichers and connectors. | View releases |
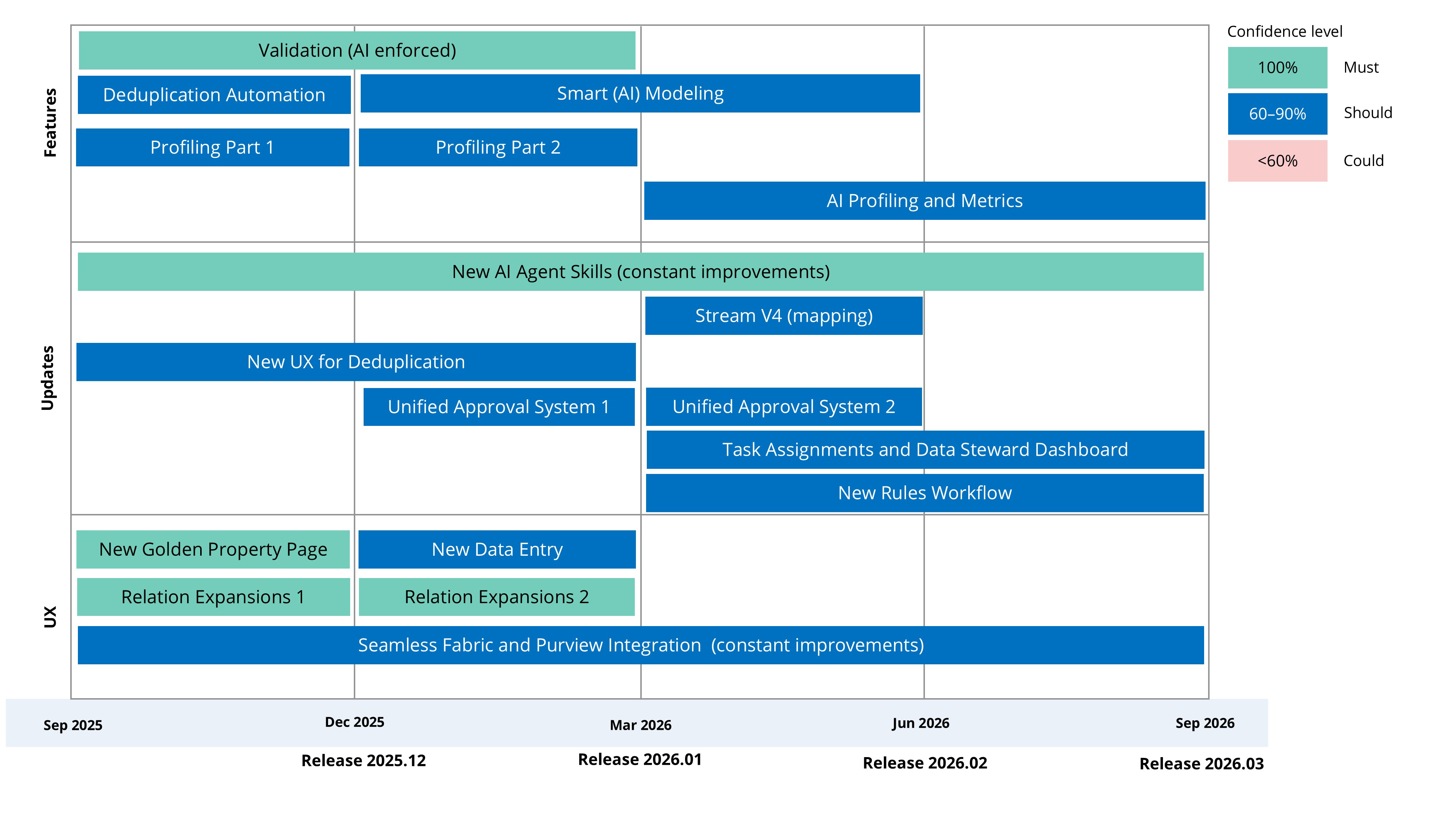
Release plan for 2025–2026
The following table outlines the features, updates, and UX improvements we plan to implement between September 2025 and September 2026.
Release plan for 2026-2027
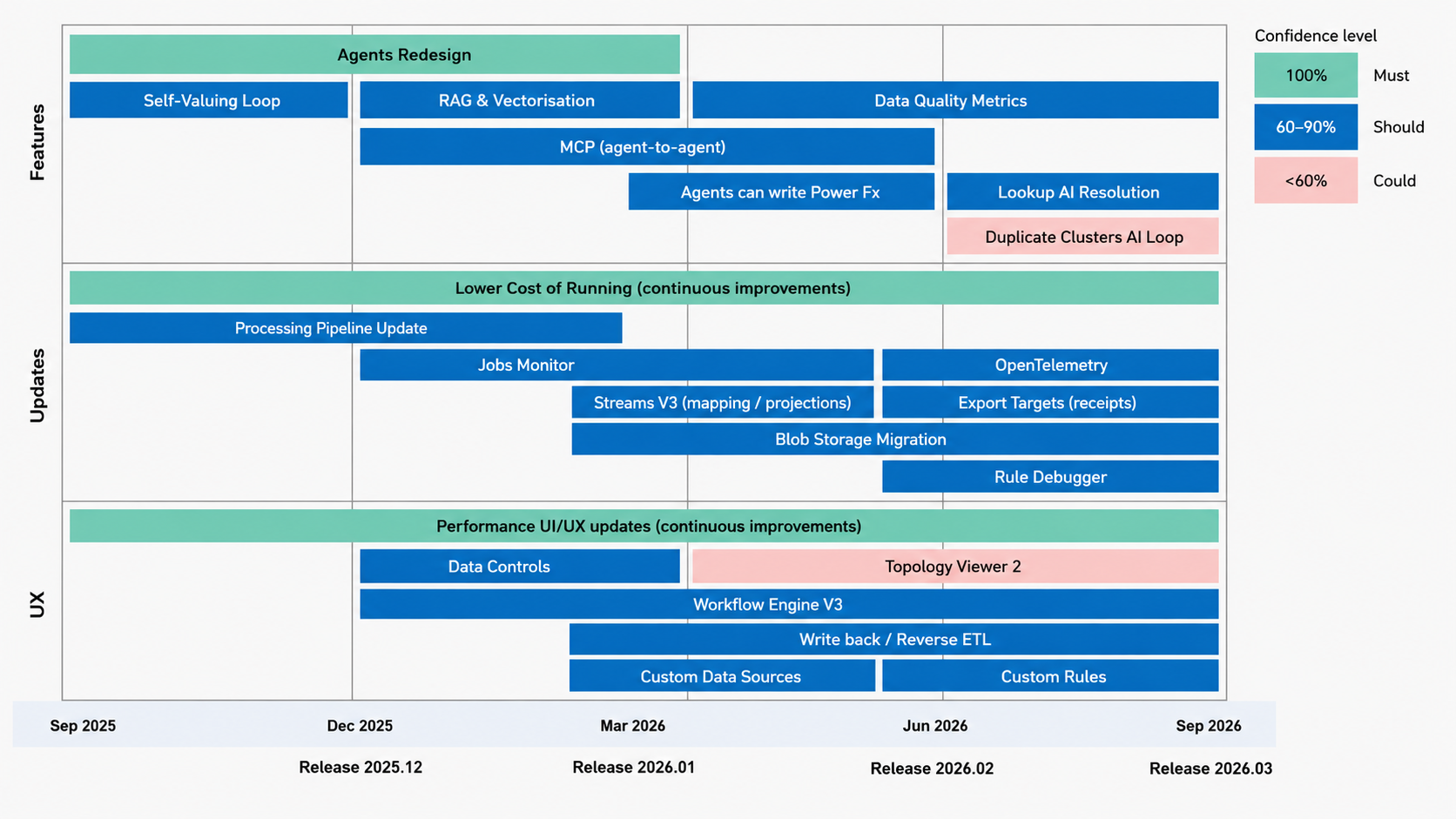
The roadmap focuses on four major investment areas:
- AI-assisted data management
- Agent-to-agent interoperability
- Platform performance, observability, and cost optimization
- Modernized data operations, workflows, and downstream activation
These improvements are designed to make CluedIn easier to operate at scale, faster to work with day to day, and more capable of supporting AI-driven master data management patterns. In fact, it is laying the foundation for an Agentic Data Management world.
Featured roadmap items
Agents Redesign
The Agents experience is being redesigned to support richer AI-assisted workflows across CluedIn. The goal is to make agents easier to configure, easier to monitor, and more effective when working with data quality, lookup resolution, deduplication, rules, and operational workflows.
Planned improvements include:
- Self-Valuing Loop – Agents will be able to evaluate the usefulness, confidence, and business value of their own outputs, allowing agent workflows to improve over time and reduce unnecessary manual review.
- RAG – Retrieval-augmented generation will allow agents to work with relevant CluedIn context, reducing hallucination risk and improving the quality of recommendations.
- Vectorisation – CluedIn will support vector-based representations of records, metadata, rules, and operational context to improve semantic matching, search, recommendations, and AI resolution workflows.
- Data Quality Metrics – Agents will use data quality signals to prioritize work, explain recommendations, and help users focus on the highest-impact remediation opportunities.
MCP
CluedIn will introduce an MCP layer designed for agent-to-agent interoperability.
This layer is intended to help other MCP-enabled systems understand how to work with CluedIn, including:
- How to query and interact with CluedIn safely
- How to handle errors and exceptions
- How to reduce unnecessary token usage
- How to optimize requests for cost, accuracy, and performance
- How to understand CluedIn’s capabilities, constraints, and recommended interaction patterns
The goal is to make CluedIn an intelligent participant in wider AI and automation ecosystems, rather than only a destination system.
Agents can write deterministic code
Agents will be able to generate Power Fx expressions for CluedIn rules and data operations.
This will help users create, test, and refine rules faster by translating natural-language intent into executable rule logic. The capability is expected to support use cases such as:
- Creating validation rules
- Generating transformation logic
- Recommending rule corrections
- Explaining existing Power Fx expressions
- Producing safer rule drafts before user approval
Performance UI/UX updates
CluedIn will continue to receive UI and UX improvements focused on performance, clarity, and day-to-day usability.
Planned updates include faster navigation, clearer operational feedback, improved page loading behavior, and more efficient user flows across key stewardship and administration areas.
Processing Pipeline Update
The processing pipeline will be updated to improve reliability, throughput, and operational visibility.
This work is expected to support larger data volumes, reduce bottlenecks, improve recovery from failed processing steps, and provide a stronger foundation for downstream observability and cost optimization.
Jobs Monitor
A new Jobs Monitor experience will provide a clearer view of active, queued, completed, failed, and retried jobs.
The goal is to make operational work easier by giving administrators and technical users a single place to understand what is running, what is blocked, and what needs attention.
OpenTelemetry
CluedIn will introduce OpenTelemetry support to improve platform observability.
This will help teams collect, correlate, and analyze telemetry across services, processing jobs, APIs, and infrastructure. The expected outcome is faster troubleshooting, better performance analysis, and improved operational confidence.
Moving Blobs to Blob Storage
Blob handling will be moved to Blob Storage to improve scalability, storage efficiency, and operational separation.
This change is expected to reduce pressure on core platform storage, improve handling of large files and payloads, and align blob management with cloud-native storage patterns.
Data Contracts
New Data Contracts will provide stronger governance and operational management over data usage, access, movement, and lifecycle.
This roadmap item is intended to support enterprise-grade controls around data quality, retention, stewardship, compliance, and downstream activation.
Streams V3
Streams V3 will introduce improvements to stream mapping and projections.
The goal is to make streams more flexible, more predictable, and easier to use when preparing data for downstream systems. Planned improvements include better projection design, clearer stream mapping, and stronger support for downstream contracts.
Export Targets receipts
Export Targets will support receipts to provide clearer confirmation of what was sent, where it was sent, and whether the receiving target accepted or processed the payload.
This will improve traceability for downstream integrations and make export operations easier to audit and troubleshoot.
Lookup AI resolution
Lookup resolution will be enhanced with AI-assisted matching and recommendation capabilities.
This will help users resolve lookup values more efficiently by suggesting likely matches, identifying ambiguous values, and reducing manual mapping effort.
Duplicate Clusters AI loop
Deduplication will be enhanced with an AI-assisted loop for duplicate clusters.
The goal is to improve duplicate review workflows by helping users understand why records are clustered, identify risky merges, recommend next actions, and continuously improve deduplication outcomes.
Rule Inspector
A new Rule Inspector will help users understand how rules execute, why specific outcomes occurred, and how rule logic can be improved.
This will make it easier to troubleshoot rules, validate changes, and reduce the risk of unexpected results in production environments.
Cost of Running Lowering
CluedIn will continue to focus on lowering the cost of running the platform.
This includes infrastructure efficiency, workload optimization, smarter processing behavior, improved storage patterns, and better observability of expensive operations.
Topology Viewer 2
Topology Viewer 2 will provide an improved way to understand platform, data, and operational topology.
The goal is to make dependencies, relationships, flows, and runtime behavior easier to visualize and diagnose.
Workflow Engine V3
Workflow Engine V3 will modernize workflow capabilities across CluedIn.
Planned capabilities include:
- Write back / Reverse ETL – Support operational activation by writing trusted data back into target systems.
- Custom Data Sources – Allow more flexible workflow-triggered ingestion and operational data source patterns.
- Custom Rules – Support more extensible, configurable workflow logic for customer-specific operating models.
Release plan
The following table outlines the proposed release grouping for the roadmap items.
| Release | Theme | Planned items |
|---|---|---|
| 2026.08.00 | AI foundation and operational improvements | Agents Redesign, Self-Valuing Loop, Processing Pipeline Update, Lower Cost of Running, Performance UI/UX updates |
| 2026.11.00 | AI-assisted modeling and platform visibility | RAG, Vectorisation, MCP, Jobs Monitor, Data Controls, Workflow Engine V3, Streams V3 foundation |
| 2027.04.00 | Observability, activation, and rule workflows | Data Quality Metrics, Agents can write Power Fx, OpenTelemetry, Blob Storage Migration, Streams V3, Export Targets receipts, Rule Debugger, Write back / Reverse ETL |
| 2027.08.00 | AI resolution and topology | Lookup AI Resolution, Duplicate Clusters AI Loop, Topology Viewer 2, Custom Rules, Workflow Engine V3 improvements |
| Continuous updates | Cross-cutting improvements | Performance UI/UX updates, Lower Cost of Running, agent skills, observability improvements, UX polish, stability fixes |
Roadmap timeline
| Roadmap item | Category | Confidence | Jul 2026 | Nov 2026 | Apr 2027 | Aug 2027 | Sep 2027 |
|---|---|---|---|---|---|---|---|
| Agents Redesign | Features | 100% | ● | ● | |||
| Self-Valuing Loop | Features | 60–90% | ● | ||||
| RAG & Vectorisation | Features | 60–90% | ● | ||||
| Data Quality Metrics | Features | 60–90% | ● | ● | ● | ||
| MCP agent-to-agent layer | Features | 60–90% | ● | ● | |||
| Agents can write Power Fx | Features | 60–90% | ● | ● | |||
| Lookup AI Resolution | Features | 60–90% | ● | ● | |||
| Duplicate Clusters AI Loop | Features | <60% | ● | ● | |||
| Lower Cost of Running | Updates | 100% | ● | ● | ● | ● | ● |
| Processing Pipeline Update | Updates | 60–90% | ● | ● | |||
| Jobs Monitor | Updates | 60–90% | ● | ● | ● | ||
| OpenTelemetry | Updates | 60–90% | ● | ● | ● | ||
| Blob Storage Migration | Updates | 60–90% | ● | ● | ● | ||
| Streams V3 mapping / projections | Updates | 60–90% | ● | ● | |||
| Export Targets receipts | Updates | 60–90% | ● | ● | |||
| Rule Debugger | Updates | 60–90% | ● | ● | |||
| Performance UI/UX updates | UX | 100% | ● | ● | ● | ● | ● |
| Data Controls | UX | 60–90% | ● | ● | |||
| Topology Viewer 2 | UX | <60% | ● | ● | ● | ||
| Workflow Engine V3 | UX | 60–90% | ● | ● | ● | ● | |
| Write back / Reverse ETL | UX | 60–90% | ● | ● | ● | ||
| Custom Data Sources | UX | 60–90% | ● | ● | |||
| Custom Rules | UX | 60–90% | ● | ● |
Release process
In this section, you will learn about our release process and the versioning of product releases. You’ll gain an understanding of the stages that CluedIn features go through before becoming generally available, as well as get to know the versioning scheme that we use to deliver changes.
Release stages
In order to prepare new and requested features, enhancements, and fixes, we follow a 6-stage release process. What is more, we are often in multiple release stages simultaneously across several releases. This approach allows us to efficiently prioritize tasks and ensure that features are released in a timely manner. By overlapping stages, we can quickly adapt to changing requirements and deliver continuous improvements.
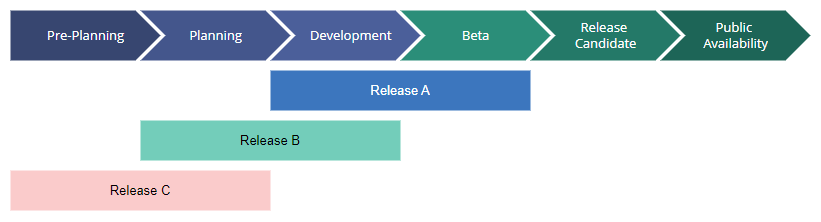
The following table describes each stage of the release process.
| Release stage | Description |
|---|---|
| Pre-Planning | This stage is dedicated to the ongoing grooming exercise to keep our backlog up to date. On conclusion of the Planning stage for a given release, we enter the Pre-Planning stage for the subsequent release. The Pre-Planning stage begins with identification of the new top 20 features and improvements and refinement efforts towards them. |
| Planning | During this stage, we assess our groomed backlog items and upcoming customer deadlines. As a result, we create a release manifest detailing expectations and timelines for a given release. |
| Development | This stage is dedicated to active development. This is where the engineering team brings the customer’s ideas to life. It is important for us to stay in communication during this phase to ensure that we are building functionality that brings value to the customer. |
| Beta | This is the first testable version of the release. This is the step where we start regression testing. While this version is available in ACR for customer use, it is not recommended to give access to it without specific relationship management. We recommend using the Beta to demo the functionality and gather feedback. Beta cannot be used in production or with real data. |
| Release Candidate | This is a stable version of the release, with potential for a few outstanding minor issues. We open the Release Candidate for testing by our internal teams and selected customers. If a customer needs specific functionality early, this is the recommended point at which they are upgraded. Even though Release Candidate is a production-ready version of the release, the release assets are not yet ready. |
| Public Availability | This is when our release becomes generally available to customers. The release can be classified as major or minor; this classification affects whether a customer should upgrade. SaaS customers are always on the latest Public Availability release. |
Product release versioning
After 2026
To support prompt delivery of patches, security fixes, and features, we use a versioning scheme that allows us to deliver changes as they are available rather than waiting for a full platform release. Starting from Jan 01, 2026, we started using a date and release version based pattern for versioning. By using dates, we can better communicate to our customers how up to date their instance of CluedIn is.
Our date-based version is divided into three parts: Year, Month, and Update.
- The
Yearis always represented as a four-digit year (e.g.2024). - The
Release Versionis always represented as a two-digit month (e.g.01for the first release of the year). - The
Updateis always represented as at least a two-digit number (e.g.01or10).
The parts of the version are then separated by . to supply the final version:
2026.01.00– this would be the first release in 2026.2026.01.01– this would be the firstupdateto the first relase of 2026.
Before 2026
To support prompt delivery of patches, security fixes, and features, we use a versioning scheme that allows us to deliver changes as they are available rather than waiting for a full platform release. Starting from June 30, 2022, we started using a date-based pattern for versioning. By using dates, we can better communicate to our customers how up to date their instance of CluedIn is.
Our date-based version is divided into three parts: Year, Month, and Update.
- The
Yearis always represented as a four-digit year (e.g.2024). - The
Monthis always represented as a two-digit month (e.g.10for October). - The
Updateis always represented as at least a two-digit number (e.g.01or10).
The parts of the version are then separated by . to supply the final version:
2024.10.00– this would be the first release in October 2024.2024.10.01– this would be the firstupdateto the October 2024 release.2024.10.14– this would be the fourteenthupdateto the October 2024 release.
Prior to date-based versioning, the CluedIn platform used a semantic versioning scheme. This is an industry standard approach to versioning that we will keep for each of the services and tools that the platform is built on (e.g., Home, Helm, Crawlers, and so on). Each tool or service is its own product and will release changes and updates as they become available.