Disaster recovery runbook with failover database
On this page
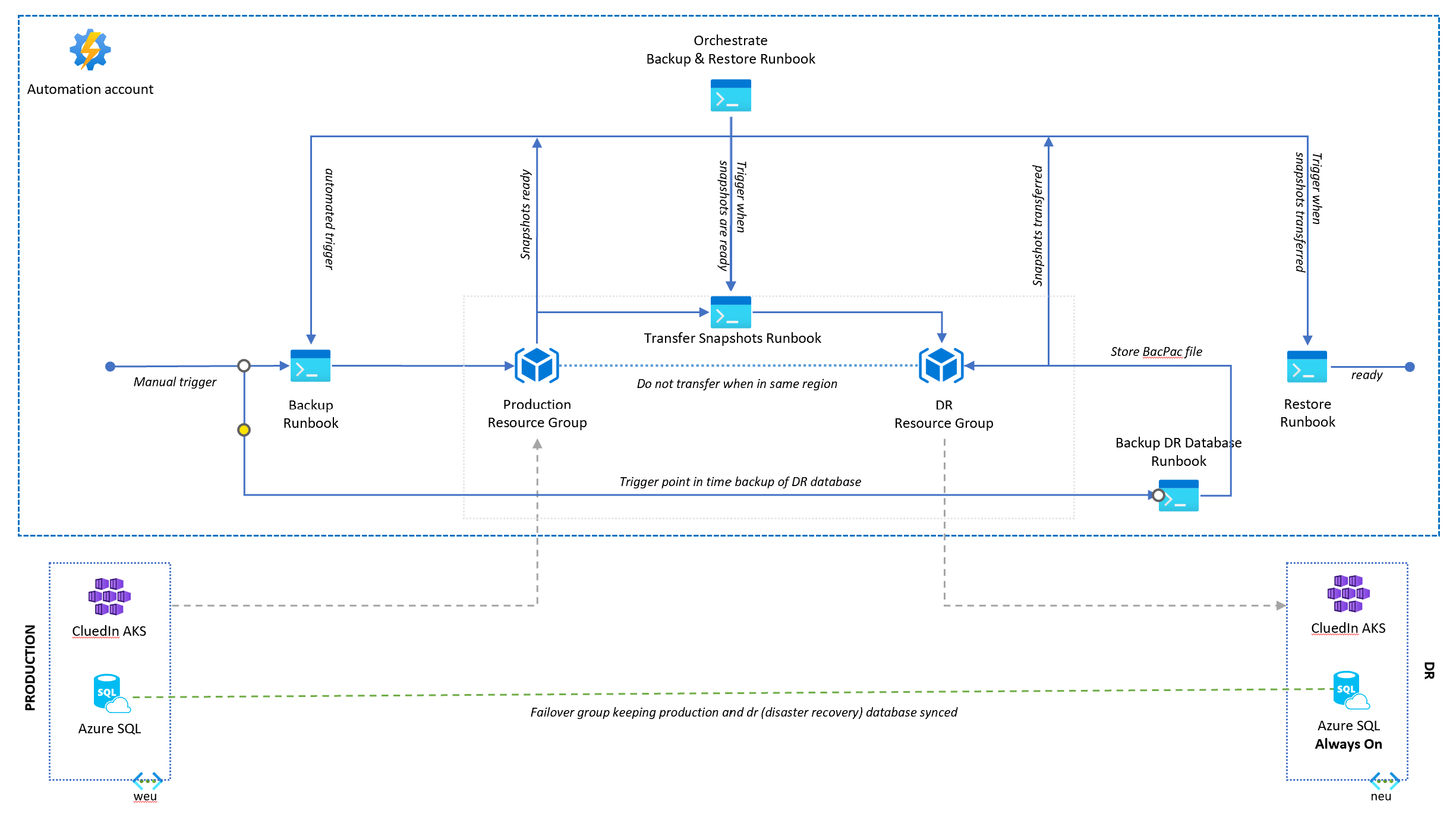
The disaster recovery runbook can be triggered manually or on a set schedule. It is responsible for orchestrating the backup > copy > restore process.
This runbook is a PowerShell script, which CluedIn will provide as needed.
This runbook is recommended for instances with larger than 1M records. Additional costs are incurred as the secondary database must always be running.
Prerequisites
- This runbook is for CluedIn versions 2025.09.00 and onwards
- Pre 2025.09.00 use Disaster recovery runbook - legacy
- An active CluedIn cluster with a valid license and a passive CluedIn cluster in a paired region
- A fail over group connecting the Azure SQL databases in the two different regions
- The runbook script
- An automation account
- The backup runbook
- The copy runbook
- The restore runbook
- A storage account
- Sufficient permissions
Automation account
An automation account must be provided. The runbook will be installed into the the automation account. The three dependent runbooks must already be installed. Typically, the runbook should be scheduled to run once a day outside of office hours.
Input parameters
| Parameter | Default | Description |
|---|---|---|
| CustomerName | required | Name of customer |
| Subscription | required | ID of the Azure subscription |
| SourceResourceGroup | required | Name of resource group where source AKS cluster is located |
| TargetResourceGroup | required` | Name of resource group where target AKS cluster is located |
| TargetStorageAccount | required | Name of target storage account |
| SourceSnapshotResourceGroup | required | Name of resource group containing source snapshots |
| TargetSnapshotResourceGroup | required | Name of resource group containing copied snapshots |
| ScaledownDR | true | Scales down a DR cluster after a successful restoer |
Process
When processing large volumes of data, cross-region transfers can be time-consuming and may significantly delay recovery. To minimize this risk, we recommend configuring a failover group to keep databases continuously synchronized across regions. This approach reduces recovery time and eliminates the need for large data transfers during a disaster event.
1. Backup of the Primary CluedIn Instance
The primary backup runbook performs the following actions:
- Takes snapshots of the virtual machine disks and stores them in a designated resource group.
The secondary backup performs the following actions:
- Exports the secondary Azure SQL databases as BACPAC files.
- Stores the BACPAC files in a designated storage account within the secondary region.
2. Transfer of Snapshots
Upon successful completion of the backups:
- Disk snapshots are transferred from the primary region to the secondary region via the Microsoft backbone.
- Transfer completion and data integrity should be validated before proceeding.
3. Disaster Recovery Environment Validation
The idle CluedIn DR instance in the secondary region is prepared and validated as follows:
- Restart the DR environment.
- Scale down all Kubernetes deployments and stateful sets.
- Restore the disks from the replicated snapshots.
- Scale the stateful sets and deployments back up.
- Verify that all services start successfully and the system operates without errors.
- After validation, scale the CluedIn environment back down to its idle state to optimize cost.
4. Azure SQL Recovery
During a failover event the secondary database should be restored via the Import Database runbook.

Scaling down of the DR environment following a successful restore is optional.